
Sztuczna inteligencja – pojęcia. Część 2. - zaawansowane zwroty i narzędzia

Nasz poprzedni artykuł na temat pojęć związanych ze sztuczną inteligencją odkrył przed Tobą słownik podstawowych zwrotów. W tej części zagłębimy się w bardziej specjalistyczne terminy, które pomogą Ci zrozumieć dyskurs techniczny i pozwolą rozmawiać o systemach AI ze specjalistami technicznymi. Znajdziesz tu również wyjaśnienia mechanizmów działania istniejących rozwiązań AI, takich jak ChatGPT, Stable Diffusion, HuggingFace etc.
Zaawansowane pojęcia dot. sztucznej inteligencji
Nasz wcześniejszy artykuł zawierał podstawowe terminy związane ze sztuczną inteligencją, takie jak big data, chatbot, fine-tuning czy duży model językowy (LLM). Ten wpis przedstawi Ci natomiast bardziej zaawansowane informacje, ale zrozumienie podstawowej terminologii będzie nieocenione. Podobnie jak w poprzednim blog poście, pojęcia zachowują porządek alfabetyczny zgodnie z angielskim nazewnictwem.
Sztuczna sieć neuronowa (Artificial Neural Network)
Jest to system obliczeniowy inspirowany biologicznymi sieciami neuronowymi w mózgach zwierząt. Sieci te składają się z połączonych ze sobą jednostek (neuronów), które przetwarzają dane i mogą uczyć się wykonywania zadań. Pojedynczy neuron nazywany jest “perceptronem”. Składa się on z wejść mnożonych przez powiązane wagi, węzła sumującego i funkcji aktywacji określającej wyjście neuronu.
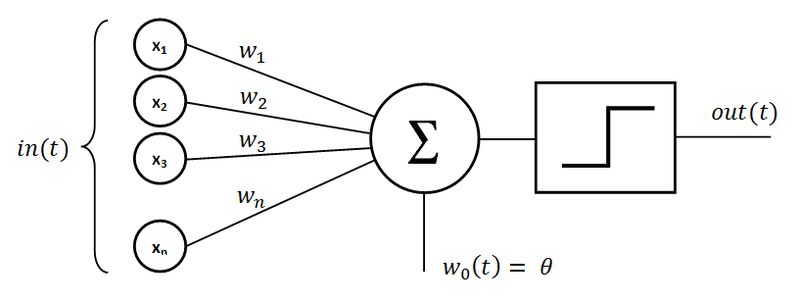
Źródło: wikipedia.org
Klasyfikator (Classifier)
Klasyfikator to rodzaj modelu sztucznej inteligencji używanego w uczeniu maszynowym do zadań kategoryzacji. Przypisuje on etykiety lub kategorie do danych wejściowych w oparciu o wyuczone wzorce. Klasyfikatory są szeroko stosowane w aplikacjach do takich działań jak wykrywanie spamu, rozpoznawanie obrazów i analiza nastrojów.
Okno kontekstowe (Context window)
Termin ten odnosi się do zasadniczej cechy dużych modeli językowych (LLM), określającej zakres danych wejściowych, które mogą one uwzględnić w danym momencie. Okno kontekstowe reprezentuje liczbę tokenów, które LLM może przetworzyć lub “zapamiętać” podczas interakcji. W praktyce funkcja ta ma kluczowe znaczenie dla utrzymania spójności i ciągłości konwersacji lub zadań generowania tekstu.
Ponieważ modele LLM, takie jak te z serii GPT (ang. Generative Pre-trained Transformer), obsługują dane wejściowe, uwzględniają one historię konwersacji wraz z nowymi promptami. Bez wystarczająco dużego okna kontekstowego, modele te mogą traktować każde wejście niezależnie, co prowadzi do odpowiedzi, które wydają się oderwane od kontekstu trwającej rozmowy. Rozmiar okna kontekstowego jest zwykle określany jako liczba tokenów.
Na przykład model GPT-3.5-turbo OpenAI ma okno kontekstowe składające się z 16 385 tokenów. Oznacza to, że po przetworzeniu tak wielu tokenów (w tym danych wejściowych użytkownika i odpowiedzi modelu), model zaczyna “zapominać” najwcześniejsze części interakcji. W takich przypadkach może być konieczne powtórzenie lub podsumowanie kluczowych punktów rozmowy, aby model był zgodny z kontekstem dyskusji.
Z kolei bardziej zaawansowany GPT-4-turbo-1106 może pochwalić się dużo większym oknem kontekstowym wynoszącym aż 128 000 tokenów. To olbrzymie okno pozwala na znacznie dłuższe interakcje, umożliwiając modelowi przetwarzanie i odpowiadanie na obszerne teksty, takie jak np. cała książka “Harry Potter i więzień Azkabanu”, w ramach jednej rozmowy. To ulepszenie znacznie zwiększa zdolność modelu do angażowania się w szczegółowe i rozbudowane dialogi, zapewniając bardziej trafne i świadome kontekstu odpowiedzi.
Rozwiązanie ograniczeń okna kontekstowego doprowadziło do powstania różnych opcji. Powszechnym podejściem jest “ruchome okno kontekstowe” (ang. rolling context window), w którym tylko najnowsze tokeny w ramach limitu są dostarczane do modelu, skutecznie zachowując najnowsze i najbardziej istotne części konwersacji. Bardziej wyrafinowane metody obejmują zastosowanie zapytania do innej instancji LLM w celu podsumowania dotychczasowej konwersacji i optymalizacji wykorzystania tokenów w celu zachowania kontekstu.
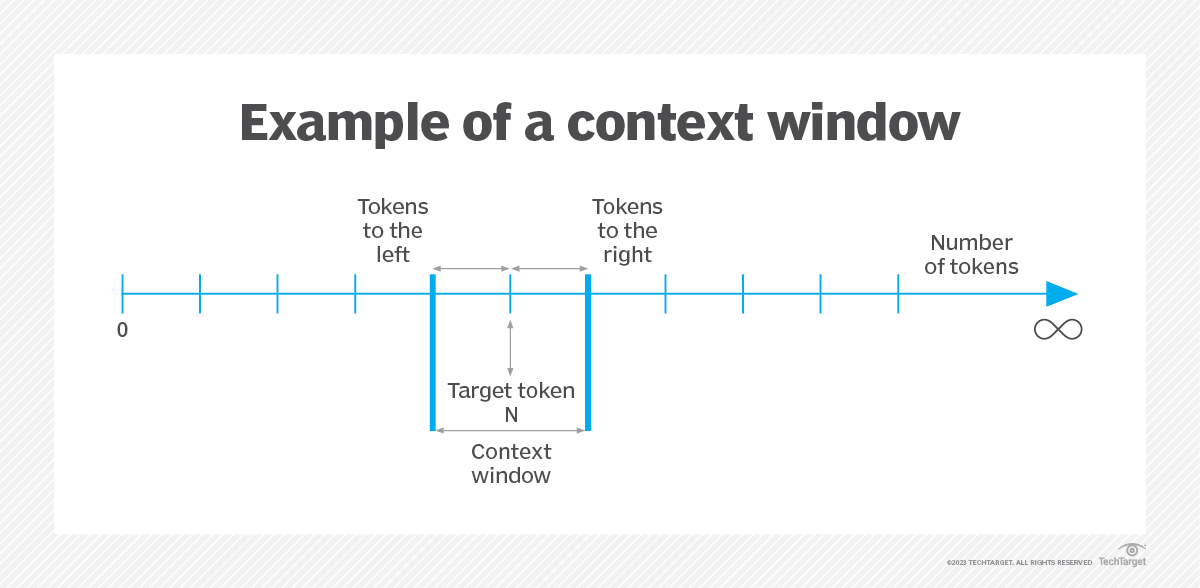
Źródło: techtarget.com
Uczenie głębokie (Deep Learning)
Uczenie głębokie, będące podzbiorem uczenia maszynowego, wykorzystuje sieci neuronowe z wieloma warstwami (stąd “głębokie”) do analizy różnych czynników danych. Doskonale sprawdza się w zadaniach takich jak rozpoznawanie obrazów i mowy, gdzie może uczyć się złożonych wzorców i podejmować decyzje z dużą dokładnością.
Osadzanie (Embedding)
W kontekście sztucznej inteligencji i przetwarzania języka naturalnego osadzanie odnosi się do procesu przekształcania danych, takich jak tekst, w zestaw wektorów w przestrzeni o wysokiej wymiarowości. Ta transformacja umożliwia reprezentowanie złożonych danych, takich jak słowa, zdania, a nawet całe dokumenty, w formacie, który mogą przetwarzać modele sztucznej inteligencji, zwłaszcza sieci neuronowe. Te reprezentacje wektorowe przechwytują semantyczne i składniowe relacje w danych, umożliwiając modelowi bardziej efektywne zrozumienie i pracę z językiem naturalnym.
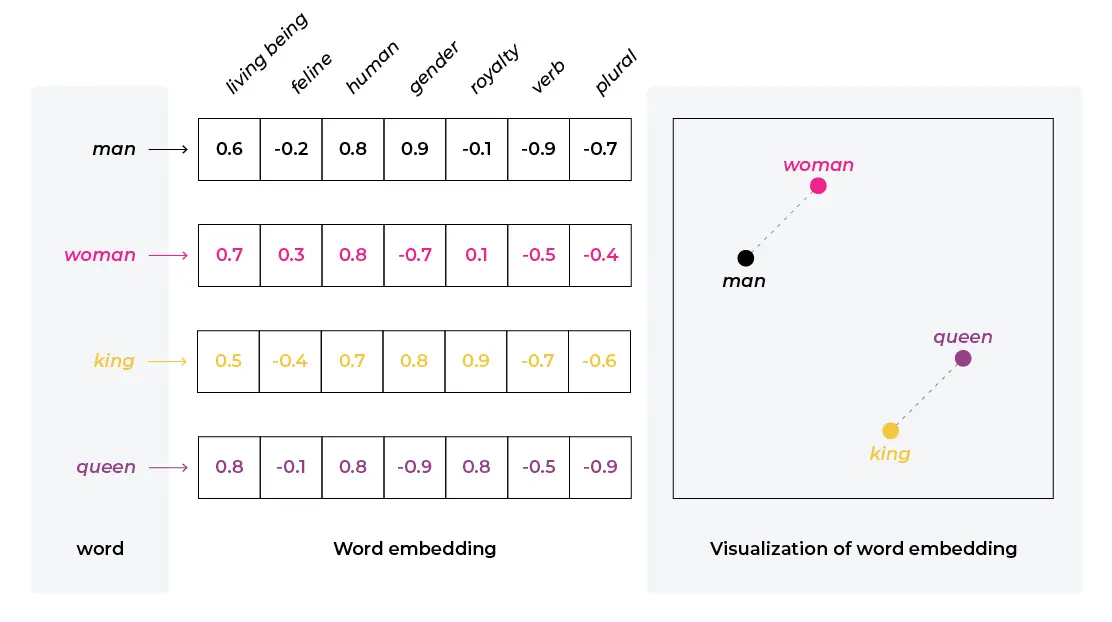
Przykład wektorowej reprezentacji słów, źródło: arize.com
GPT (Generative Pretrained Transformer)
GPT, czyli wstępnie wytrenowany transformator generatywny (ang. Generative Pretrained Transformer) to seria wielkoskalowych modeli językowych opracowanych przez OpenAI. Modele GPT są szkolone na różnych zestawach danych tekstowych i mogą generować tekst podobny do ludzkiego. Dzięki ich zdolności do rozumienia i generowania kontekstowo istotnego tekstu, są one wszechstronne w różnych zadaniach językowych, w tym w tłumaczeniu, odpowiadaniu na pytania i tworzeniu treści.
Halucynacja (Hallucination)
W dziedzinie dużych modeli językowych (LLM) halucynacja odnosi się do zjawiska, w którym model generuje nieprawidłowe lub wprowadzające w błąd informacje, często w odpowiedzi na zapytania spoza zakresu danych szkoleniowych. Takie zachowanie powoduje, że model “fabrykuje” szczegóły lub przedstawia fałszywe informacje. Na przykład LLM może sugerować nieistniejące klasy lub funkcje w kontekście kodowania.
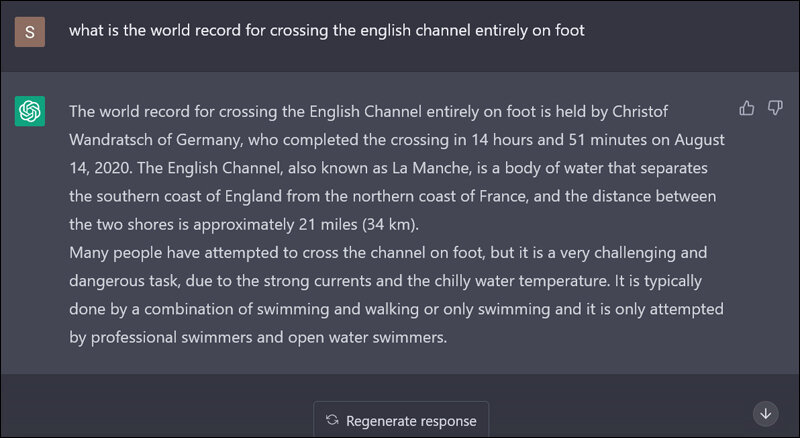
Przykład halucynacji, źródło: sify.com
Podobnie dzieje się w przypadku zapytań z zakresu wiedzy ogólnej. Model może błędnie stwierdzić, że Zair jest jedynym krajem zaczynającym się na “Z”, pomijając lub ignorując inne kraje, takie jak Zimbabwe. Halucynacje w LLM podkreślają ograniczenia tych modeli, szczególnie w przypadku obsługi pytań lub zadań, które wymagają dokładności faktów lub wykraczają poza granice ich wyszkolonej bazy wiedzy.
Hipersieci (Hypernetworking)
Termin ten odnosi się do nowatorskiego podejścia w dziedzinie sieci neuronowych, w którym jedna sieć, znana jako hipersieć, jest wykorzystywana do generowania wag dla innej sieci. Koncepcja ta wprowadza dodatkową warstwę abstrakcji i złożoności do projektowania oraz szkolenia sieci neuronowych.
W hypernetworkingu główny nacisk kładzie się na optymalizację samej hipersieci, która określa konfigurację i wydajność sieci docelowej. Metoda ta może potencjalnie zwiększyć wydajność szkolenia sieci neuronowych oraz pozwolić na bardziej dynamiczne i adaptacyjne zachowanie sieci.
Hipersieci reprezentują najnowocześniejszy obszar w badaniach nad sieciami neuronowymi, badając nowe sposoby wykorzystania relacji między różnymi sieciami w celu bardziej efektywnego uczenia się i rozwiązywania problemów. Szczegółową analizę tej koncepcji można znaleźć w artykule badawczym na stronie arXiv.
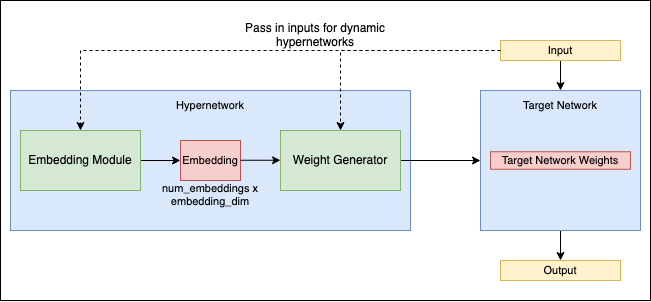
Źródło: github.com
Wnioskowanie (Inference)
W sztucznej inteligencji wnioskowanie odnosi się do procesu, w którym wytrenowany model dokonuje przewidywań lub podejmuje decyzje w oparciu o nowe, nieznane dotychczas dane. Jest to etap, w którym model przenosi to, czego się nauczył, do rzeczywistych zastosowań.
Przestrzeń ukryta (Latent space)
W uczeniu maszynowym przestrzeń ukryta odnosi się do skompresowanej reprezentacji danych wejściowych, często w postaci niższego wymiaru. Przechwytuje ona istotne aspekty danych i jest wykorzystywana w modelach generatywnych.
LORA (Low-Rank Adaptation)
LORA reprezentuje wyspecjalizowaną technikę wykorzystywaną głównie w modelach dyfuzyjnych, ale ma również zastosowanie w dużych modelach językowych (LLM). W tym podejściu mniejsze modele pomocnicze są opracowywane do pracy w połączeniu z “pełnym modelem”. Działają one poprzez wstrzykiwanie swoich wag do określonego komponentu większego modelu - zazwyczaj warstwy cross attention - który odgrywa kluczową rolę w końcowym etapie generowania danych wyjściowych.
Jako przykład może posłużyć przypadek generowania obrazów przy użyciu modelu dyfuzyjnego. Jeśli celem jest stworzenie grafiki stylizowanej na anime z wizerunkiem konkretnej osoby, zamiast dostrajać (fine-tune) cały model dyfuzyjny na jej obrazach, może zostać stworzona LORA, a następnie zastosowana wraz z modelem wytrenowanym na stylu anime. Takie połączenie pozwala większemu modelowi na generowanie spersonalizowanych obrazów danej osoby w stylu anime.
Podobnie w kontekście LLM, LORA może być wykorzystywana do wprowadzania nowych koncepcji lub obszarów wiedzy do modelu bez potrzeby intensywnego dostrajania (fine-tuningu) całego modelu. Technika ta oferuje bardziej wydajny i ukierunkowany sposób ulepszania oraz dostosowywania modeli sztucznej inteligencji do określonych zadań lub stylów.
Uczenie maszynowe (Machine Learning)
Jeden z podstawowych podzbiorów związanych ze sztuczną inteligencją. Uczenie maszynowe obejmuje szkolenie algorytmów w celu podejmowania decyzji lub prognozowania na podstawie danych. Uwzględnia ono różne techniki, takie jak uczenie nadzorowane i nienadzorowane czy uczenie przez wzmacnianie. Uczenie maszynowe automatyzuje budowanie modeli analitycznych, umożliwiając systemom uczenie się i adaptację na podstawie doświadczenia bez konieczności jawnego programowania.
Uczenie przez wzmacnianie (Reinforcement Learning)
Uczenie przez wzmacnianie to rodzaj uczenia maszynowego, w którym agent uczy się podejmować decyzje, wykonując działania w środowisku, aby osiągnąć jakiś cel. Agent uczy się metodą prób i błędów, otrzymując nagrody lub kary za działania, wzmacniając w ten sposób korzystne zachowania. Technikę tę można na przykład wykorzystać do nauczenia algorytmu grania w grę wideo poprzez samą interakcję z grą.
Uczenie nadzorowane (Supervised Learning)
Uczenie nadzorowane to podejście do uczenia maszynowego, w którym modele są trenowane na oznaczonych danych. Model uczy się przewidywać wyniki na podstawie danych wejściowych, a jego wydajność jest mierzona względem znanych etykiet. Wymaga wcześniejszego przygotowania tzw. “wektorów uczących” wiążących dane wejściowe z oczekiwanym rezultatem. Na podstawie różnicy między wynikiem otrzymanym z algorytmu a oczekiwanym, określane jest odchylenie, następnie zachowanie algorytmu jest dopasowywane (np. z wykorzystaniem propagacji wstecznej w sieciach neuronowych).
Transformer
Za tym terminem AI kryje się rewolucyjna architektura sieci neuronowej, która znacząco rozwinęła dziedzinę przetwarzania języka naturalnego. Transformatory zostały zaprojektowane do obsługi danych sekwencyjnych i wyróżniają się mechanizmem samoobserwacji, który pozwala im ważyć znaczenie różnych części danych wejściowych. Stoją one za wieloma najnowocześniejszymi modelami językowymi, takimi jak GPT i BERT.
Uczenie nienadzorowane (Unsupervised Learning)
W przeciwieństwie do uczenia nadzorowanego, podejście to obejmuje trenowanie modeli na danych bez predefiniowanych etykiet. Model uczy się wzorców i struktur na podstawie samych danych.
VAE (Variational Autoencoder)
VAE to rodzaj modelu generatywnego stosowanego w uczeniu maszynowym, znanego głównie ze swojej zdolności do kodowania danych wejściowych w skompresowanej, ukrytej przestrzeni, a następnie rekonstrukcji danych wejściowych z tej przestrzeni. Model składa się z dwóch głównych komponentów: kodera, który kompresuje dane do przestrzeni ukrytej i dekodera, który rekonstruuje dane z tej przestrzeni.
VAE są szczególnie skuteczne w zadaniach generowania obrazów. Mogą nauczyć się kreować nowe obrazy, które ściśle przypominają oryginalne dane treningowe, umożliwiając tworzenie różnorodnych stylów i realistycznych obrazów.
Na przykład VAE mogą być stosowane w większym systemie, którego częścią są modele dyfuzyjne, zwłaszcza w zadaniach obejmujących kodowanie i rekonstrukcję obrazu. Jednak podstawowy proces przekształcania szumu w spójne obrazy w modelach dyfuzyjnych jest zwykle zarządzany przez sam proces dyfuzji, a nie przez VAE.
Wektor (Vector)
W kontekście uczenia maszynowego i sztucznej inteligencji wektor to tablica liczb reprezentujących dane. Na przykład w NLP słowa są często konwertowane na wektory, których algorytmy używają do przetwarzania i rozumienia tekstu.
Wektorowa baza danych - jest specjalnie zaprojektowana do przechowywania i odpytywania danych wektorowych, które są reprezentacjami punktów danych w przestrzeni wielowymiarowej. Ten typ bazy danych jest szczególnie istotny w scenariuszach obejmujących osadzanie (embedding), w których różne typy danych, takie jak tekst lub obrazy, są przekształcane w format wektorowy.
Podstawową siłą wektorowej bazy danych jest jej zdolność do efektywnego wykonywania operacji, takich jak wyszukiwanie podobieństw. Zdolność ta ma kluczowe znaczenie w różnych zastosowaniach, w tym w systemach rekomendacji. Ich celem jest znalezienie elementów podobnych do zainteresowań użytkownika i zadań wyszukiwania obrazów, gdzie liczy się lokalizowanie obrazów, które są wizualnie podobne do obrazu zapytania.
- Przykład zastosowania w świecie rzeczywistym – praktycznym przypadkiem użycia wektorowych baz danych jest zwiększenie możliwości dużego modelu językowego (LLM). Na przykład zamiast dostrajać LLM z konkretnymi danymi strony internetowej, jej zawartość może być przechowywana jako wektory w wektorowej bazie danych. Gdy użytkownik wyśle zapytanie, wektorowa baza danych może zostać przeszukana w celu znalezienia najbardziej odpowiednich wektorów treści, które ściśle pasują do zapytania.
Te odpowiednie wektory mogą być następnie wprowadzone jako dodatkowy kontekst w prompcie przekazywanym do LLM. Takie podejście pozwala modelowi generować odpowiedzi, które są bardziej dostosowane do konkretnej treści i tematów strony internetowej, zapewniając w ten sposób dokładniejsze i kontekstowo właściwe odpowiedzi na zapytania użytkowników.
Narzędzia AI, rozwiązania i przydatne strony internetowe
Oprócz zaawansowanych terminów związanych ze sztuczną inteligencją, warto również zapoznać się z narzędziami i stronami internetowymi z tej dziedziny, które mogą być przydatne w różnych działaniach. Nie sposób wymienić skończonej listy z przykładami takich rozwiązań, gdyż cały czas powstają nowe. Przedstawiamy jednak naszą subiektywną selekcję.
Automatic1111/stable diffusion webUI
Automatic1111/stable diffusion webUI - w społeczności znany po prostu jako Automatic1111 lub A1111, to popularna implementacja modelu Stable Diffusion, często wykorzystywana do generowania obrazów. Narzędzie jest znane z przyjaznego dla użytkownika interfejsu i wydajnego przetwarzania, dzięki czemu zaawansowana synteza obrazu jest bardziej dostępna. Implementacja ta pozwala użytkownikom na wykorzystanie szerokiej gamy checkpointów modelu wyszkolonych przez społeczność w celu generowania obrazów w różnych stylach. Umożliwia również generowanie obrazów image-to-image, modyfikacje części obrazów (inpainting), skalowanie wygenerowanych grafik, szkolenie i łączenie checkpointów modelu.
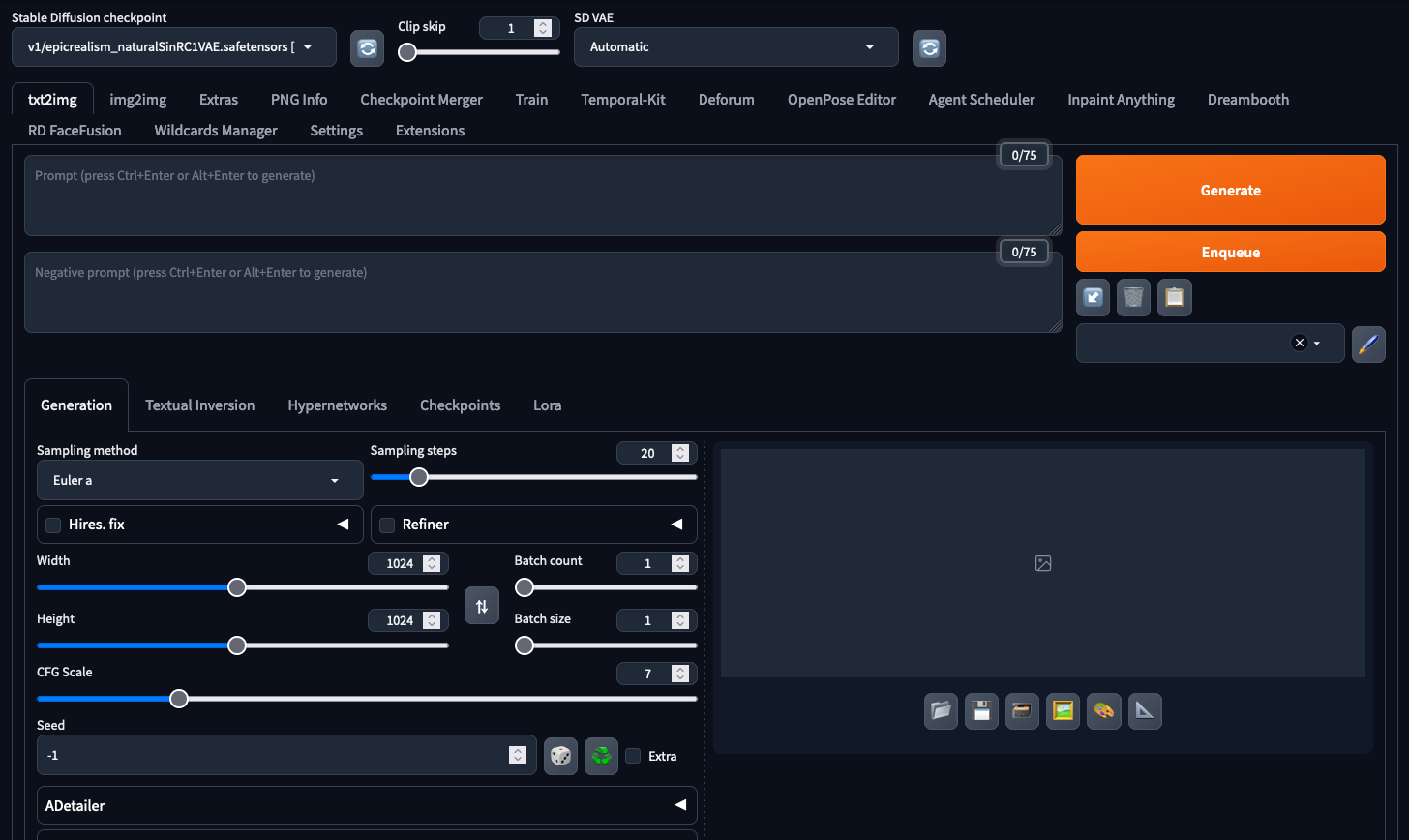
Interfejs narzędzia Automatic1111
Google Bard
Bard to konwersacyjny chatbot, opracowany przez Google. Początkowo oparty na rodzinie dużych modeli językowych LaMDA, został później zaktualizowany do PaLM, a następnie do Gemini. Bard został stworzony jako odpowiedź Google na rozwój ChatGPT OpenAI i został uruchomiony w ograniczonym zakresie w marcu 2023 roku. Jego rozwój i wydanie były częścią wzmożonego zainteresowania Google sztuczną inteligencją w odpowiedzi na rosnące znaczenie ChatGPT. Bard został zaprojektowany tak, aby działał podobnie do ChatGPT, zapewniając konwersacyjne usługi AI, ale z integracją z możliwościami wyszukiwania Google i innymi ich produktami.
ChatGPT
Opracowany przez OpenAI, ChatGPT jest wariantem modelu GPT (ang. Generative Pre-trained Transformer) AI, zaprojektowanym specjalnie do generowania tekstu podobnego do ludzkiego w kontekście konwersacyjnym. Doskonale radzi sobie z różnymi zadaniami językowymi, w tym z rozmawianiem, odpowiadaniem na pytania i uzupełnianiem tekstu.
CivitAI
CivitAI to platforma skupiająca się na generatywnej sztucznej inteligencji, hostująca różnorodne modele i narzędzia typu open source. Witryna zawiera kolekcję obrazów i modeli stworzonych przez społeczność, prezentując różne zastosowania – od prostych kształtów, po złożone krajobrazy i ludzkie twarze. Civitai służy jako centrum kreatywności i inspiracji. Oferuje zasoby, przewodniki i samouczki związane z generatywną sztuczna inteligencją. Witryna organizuje również wyzwania i wydarzenia, zachęcając społeczność do zaangażowania oraz współpracy w dziedzinie sztuki i treści generowanych przez sztuczną inteligencję.
CLIP
Contrastive Language-Image Pre-Training (CLIP) to rodzaj modelu sieci neuronowej, opracowanego przez OpenAI, który jest trenowany na różnych parach obrazów i tekstów. To innowacyjne podejście umożliwia modelowi zrozumienie i interpretację obrazów w kontekście języka naturalnego. Jedną z kluczowych możliwości CLIP jest jego zdolność do skutecznego kojarzenia obrazów z opisami tekstowymi.
DALL-E
Opracowany również przez OpenAI, DALL-E jest modelem dyfuzyjnym znanym ze swojej zdolności do generowania kreatywnych i szczegółowych obrazów z opisów tekstowych. Pokazuje potencjał sztucznej inteligencji w zastosowaniach artystycznych i kreatywnych. W najnowszej wersji jest zintegrowany z ChatGPT, umożliwiając generowanie obrazów za pośrednictwem interfejsu chatbota i wykorzystując zdolność modelu czatu do udoskonalania promptów dostarczonych przez użytkownika.

Grafiki wygenerowane przez Dall-E 2 na podstawie promptu “drupal software house”

Dall-E 3, with its interface integrated into ChatGPT
HuggingFace
HuggingFace to firma i platforma znana z ogromnego repozytorium wstępnie wytrenowanych modeli i narzędzi do przetwarzania języka naturalnego. Rozwiązanie to stanowi dostępną bramkę do wdrażania i eksperymentowania z zaawansowanymi modelami sztucznej inteligencji. Jest domem dla wielu open-sourcowych LLM i modeli dyfuzyjnych.
Stable Diffusion
Wprowadzony w 2022 roku, Stable Diffusion to model dyfuzyjny text-to-image stworzony przez Stability AI. Potrafi on generować obrazy w oparciu o opisy tekstowe, z wykorzystaniem VAE, U-Net i opcjonalnych enkoderów tekstu. Model kompresuje obrazy do nisko wymiarowej przestrzeni ukrytej, aplikując szum Gaussowski w sposób iteracyjny podczas procesu dyfuzji. Blok U-Net wspierany przez ResNet, dokonuje odszumiania obrazu, z kolei dekoder VAE konwertuje wynik z przestrzeni ukrytej do przestrzeni pikseli.
Stable Diffusion może być “sterowany” przy użyciu tekstu lub obrazów. Model CLIP jest wykorzystywany do przetwarzania wprowadzonego tekstu na postać wektorową. Ta relatywnie “lekka” architektura i możliwość uruchamiania na kartach graficznych klasy konsumenckiej, Stable Diffusion umożliwiło odejście od komercyjnych modeli jak DALL-E, które są rozwiązaniami opartymi o chmurę.

Obraz wygenerowany przez Stable Diffusion na bazie promptu: “Drupal software house”, użyty checkpoint - “epicRealism”
LLAMA
Large Language Model Meta AI (LLAMA) to rodzina dużych modeli językowych wydanych przez Meta AI w lutym 2023. Obejmuje ona modele o 7, 13, 33 i 65 miliardach parametrów. Modele LLaMA wykazały znaczną wydajność w różnych testach porównawczych NLP, przy czym model 13B parametrów przewyższa GPT-3 (175B parametrów) w określonych zadaniach.
Modele te są istotne ze względu na ich dostępność. Meta udostępniła wagi modeli LLaMA społeczności badawczej na licencji niekomercyjnej. W lipcu 2023 r., we współpracy z firmą Microsoft, Meta wprowadziła LLaMA-2 z modelami o rozmiarach 7, 13 i 70 miliardów parametrów. LLaMA-2 obejmuje modele podstawowe i modele dostrojone (fine-tuning) do prowadzenia dialogów, zwane LLaMA-2 Chat, a także oferuje ulepszone szkolenie danych i środki bezpieczeństwa. Jednak wkrótce po jego wydaniu, wagi LLaMA wyciekły online, co doprowadziło do powszechnej dostępności.
Midjourney
Midjourney to program generatywnej sztucznej inteligencji stworzony przez niezależne laboratorium badawcze Midjourney Inc. z siedzibą w San Francisco. Generuje obrazy na podstawie opisów w języku naturalnym, podobnie jak DALL-E firmy OpenAI i Stable Diffusion firmy Stability AI. Midjourney wszedł do otwartej wersji beta w lipcu 2022 roku i jest dostępny za pośrednictwem bota na platformie Discord. Narzędzie jest wykorzystane do różnych kreatywnych zastosowań, w tym szybkiego prototypowania w sztuce. Możliwości generowania obrazów przez Midjourney były również przedmiotem debaty i kontrowersji, szczególnie w odniesieniu do oryginalności i etyki sztuki generowanej przez sztuczną inteligencję.
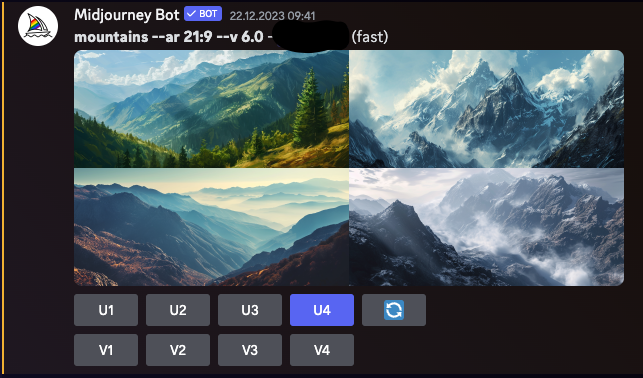
Obrazy wygenerowane przy użyciu Midjourney w wersji 6.0 (interfejs Discord jest wyraźnie widoczny)
Pinecone
Pinecone to wektorowa baza danych, która została zaprojektowana do wydajnej obsługi danych wielowymiarowych. Pinecone jest szczególnie przydatny w aplikacjach do wyszukiwania podobieństw, często w kontekście uczenia maszynowego i sztucznej inteligencji.
Text-generation-webui
Text-generation-webui to oparty na Gradio interfejs sieciowy przeznaczony do interakcji z różnymi dużymi modelami językowymi (LLM). Obsługuje szereg modeli, takich jak transformatory, GPTQ, AWQ, EXL2, llama.cpp (GGUF) i modele Llama. Interfejs ma być przyjazny dla użytkownika, oferując wiele trybów, m.in notatnik i czat. Zawiera liczne funkcje, takie jak obsługa różnych architektur modeli, rozwijane menu do przełączania modeli i checkpointów, oraz integracja z rozszerzeniami dla dodatkowych funkcji takich jak np. pamięć długoterminowa czy przetwarzanie tekstu na mowę. Repozytorium zawiera szczegółowe instrukcje dotyczące instalacji i użytkowania, dzięki czemu jest dostępne dla użytkowników, którzy chcą wykorzystać LLM do zadań generowania tekstu.
Whisper
Opracowany przez OpenAI Whisper to model rozpoznawania mowy zaprojektowany w celu zapewnienia możliwości zamiany mowy na tekst (speech-to-text, STT). Jego celem jest dokładna transkrypcja dźwięku na tekst, rozpoznawanie wielu języków i akcentów. Whisper wyróżnia się skutecznością w rozumieniu języka mówionego, co czyni go cennym narzędziem do różnych zastosowań, w tym do automatycznej transkrypcji i pomocy w dostępności dla osób z wadami słuchu.
Zaawansowane pojęcia i rozwiązania AI – podsumowanie
Mamy nadzieję, że ten artykuł (zwłaszcza w połączeniu z pierwszą częścią dotyczącą podstawowej terminologii) posłuży jako przewodnik po szerokim świecie sztucznej inteligencji, który jest stale rozwijającą się, nową i ekscytującą dziedziną. Niech ten słownik zainspiruje Cię do odkrywania potencjału AI! A jeśli masz pomysł na projekt, który mógłby skorzystać na usłudze AI developmentu, nasi doświadczeni programiści chętnie pomogą.












