
Niezawodne środowisko przy użyciu AWS

Serwisy internetowe odgrywają w sieci coraz bardziej istotną rolę, niekiedy generując olbrzymie zyski ze swojej działalności. Nawet najdrobniejsze przerwy w ich działaniu potrafią przynieść straty, liczone w setkach czy nawet tysiącach dolarów. Dlatego w Droptica przywiązujemy ogromną wagę do tego, by nasze usługi Drupal developmentu były możliwie niezawodne. Jak? Dzięki rozwiązaniom gwarantującym wysoką dostępność oferowanym przez Amazon Web Services.
Czym jest wysoka dostępność?
Na potrzeby tego artykułu wysoką dostępność (ang. high availability, HA) zdefiniujmy jako wymaganie wobec serwisu internetowego dotyczące jego czasu działania, określone procentem czasu działania w miesiącu. 100% dostępności oznacza, że użytkownicy mogą korzystać z danej strony przez 43 200 minut, czyli dokładnie 30 dni.
Jeżeli z jakiegoś powodu, nieważne czy jest to aktualizacja, awaria lub atak, usługa nie będzie działała poprawnie przez 12 godzin, parametr dostępności osiągnie wartość 98.3% (42 480 minut działania z 43 200).
Jak wysokiej dostępności potrzebujemy?
Na to pytanie nie ma jednoznacznej odpowiedzi, gdyż w głównej mierze zależy to od wymagań zdefiniowanych przez klienta. Jeżeli ten nie określił takiego parametru - musimy to zrobić sami. W takim wypadku warto odpowiedzieć na dwa krótkie pytania:
- ile czasu pochłaniają aktualizacje serwisu (wymagające wyłączenia strony dla użytkowników),
- ile czasu należy poświęcić na inne działania wymagające wyłączenia serwisu.
Suma dwóch odpowiedzi, powiększona o ewentualny bufor bezpieczeństwa, pozwala na określenie pożądanego czasu dostępności. W Droptica, dla naszych kluczowych stron, parametr ten wynosi 99.99%, co przekłada się na zaledwie 4 minuty braku dostępu do usług w ciągu całego miesiąca!
Co wyróżnia infrastrukturę HA?
W standardowym podejściu, wykorzystywanym na wielu platformach hostingowych, mamy do czynienia z jednym serwerem, na którym skonfigurowane są wszystkie niezbędne do świadczenia usługi aplikacje, takie jak serwer HTTP (apache2 lub nginx), MySQL, czasami również solr, redis, memcached i oczywiście przestrzeń dyskowa. Schemat takiego rozwiązania przedstawiamy na poniższym rysunku.
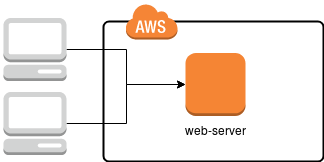
W takim wypadku wystarczy, aby uszkodzeniu uległ jeden serwer (lub któryś z zainstalowanych komponentów) i cały utrzymywany tam serwis przestaje działać, obniżając czas dostępności. Jak temu zapobiec? W dużym uproszczeniu wystarczy powielić infrastrukturę tak, by w razie awarii któregoś z serwerów jego zadania przejął inny, tak jak przedstawione zostało to na poniższym schemacie.
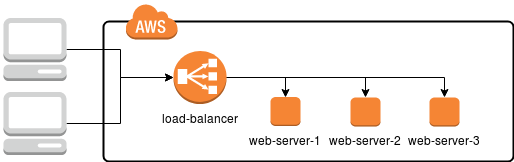
Przy takim podejściu każdy z serwerów WWW (web-server-1, web-server-2 i web-server-3) ma taką samą funkcjonalność i wystawia dokładnie takie same usługi i serwisy. Natomiast na drodze do użytkownika pojawia się dodatkowo load balancer, specjalny serwer, którego zadaniem jest odebranie żądania użytkownika i skierowanie na jedną z trzech maszyn docelowych.
W prawdzie na rysunku load-balancer występuje jako pojedynczy element i może się wydawać, że teraz on przejmuje rolę węzła najbardziej podatnego na awarię, to w praktyce Amazon dostarcza szereg rozwiązań skalowalnych, wydajnych i niezawodnych udostępniających funkcję load balanacera - są to:
Praktyczny przykład
W Droptice, w odpowiedzi na zapotrzebowanie wielu klientów, przygotowaliśmy schemat który w większości przypadków spełnia nasze wymagania. Infrastruktura zgodna z takimi założeniami (rysunek poniżej) zapewnia redundancję i wysoką dostępność, stosunkowo niewielkim kosztem.
W tym celu korzystamy z czterech rozwiązań przygotowanych przez Amazon:
- Maszyny EC2 - trzon całego środowiska czyli wirtualne maszyny na których uruchomiony jest serwis,
- Application Load Balancer (ALB) - load balancer, który dynamicznie rozkłada ruch pomiędzy instancjami EC2, wykrywa ich awarie oraz obsługuje ruch HTTPS,
- Relational Database Service (RDS) - rozproszona usługa bazy danych end-to-end (MySQL),
- Elastic File System (EFS) - rozproszony system plików - trzymamy tutaj współdzielone dane, takie jak obrazy, multimedia, pliki przesłane przez użytkowników.
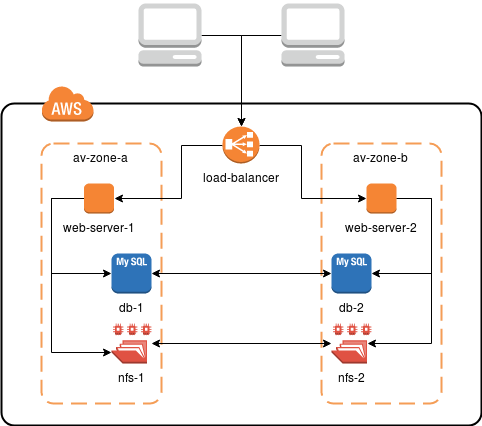
W powyższym przykładzie wszystkie komponenty infrastruktury są zdefiniowane podwójnie w różnych strefach (ang. availability zone). Fizycznie są to dwa różne centra danych, połączone szybkimi i stabilnymi łączami. Dzięki zastosowaniu EFS i RDS nie musimy się przejmować konfiguracją usług i synchronizacją danych. Po prostu je używamy - do RDS dostajemy dane do MySQL, a EFS montuje się na serwerze jak zwykły share NFS.
Problemy związane z wysoką dostępnością
Wdrożenie systemów high availability nie tylko przynosi mnóstwo korzyści, ale potrafi również sprawić wiele problemów. Dzieje się tak dlatego, że wprowadzamy do środowiska znacznie bardziej skomplikowane struktury.
Jednym z pierwszych procesów, który ulega znacznemu skomplikowaniu, jest deployment aplikacji. Należy go dostosować do obsługi wielu serwerów tak, by nie doprowadzić do sytuacji, gdzie na jednym hoście aplikacja aktualizuje bazę danych, a na drugim trwa właśnie wtedy obsługa ruchu użytkowników.
W kwestii różnic pomiędzy poszczególnymi usługami pojawia się również problem tych, które operują na plikach - na przykład Solr. Uruchomienie trzech instancji działających niezależnie doprowadzi do sytuacji, gdzie jedne instancje będą mniej lub bardziej aktualne niż pozostałe. Z pomocą przychodzi tutaj współdzielony system plików (NFS, EFS, itp.), klaster Solr lub dedykowane rozwiązania jak CloudSearch.
Zdecydowanie trudniejsze staje się przeglądanie logów. Ruch związany z konkretną sesją użytkownika kierowany jest na różne serwery, dlatego dobrą praktyką będzie przygotowanie centralnego punktu logowania na przykład w oparciu o Logstash.
Zasadniczą wadą wdrażania infrastruktury wysokiej dostępności są też koszty. Większość serwerów i usług musimy bowiem udostępniać równolegle, przynajmniej podwójnie, a czasami i w większej ilości. W prawdzie mogą to być serwery o mniejszej wydajności (wszak ruch jest rozrzucany w miarę proporcjonalnie), to w ogólnym rozrachunku, po uwzględnieniu również kosztów klastrów aplikacji - wyjdzie drożej, znacznie drożej. Z drugiej strony jednak jest to inwestycja, która owocuje mniejszym stresem i pewnością, że w razie awarii wciąż będziemy w stanie dostarczać treści do użytkownika końcowego.








