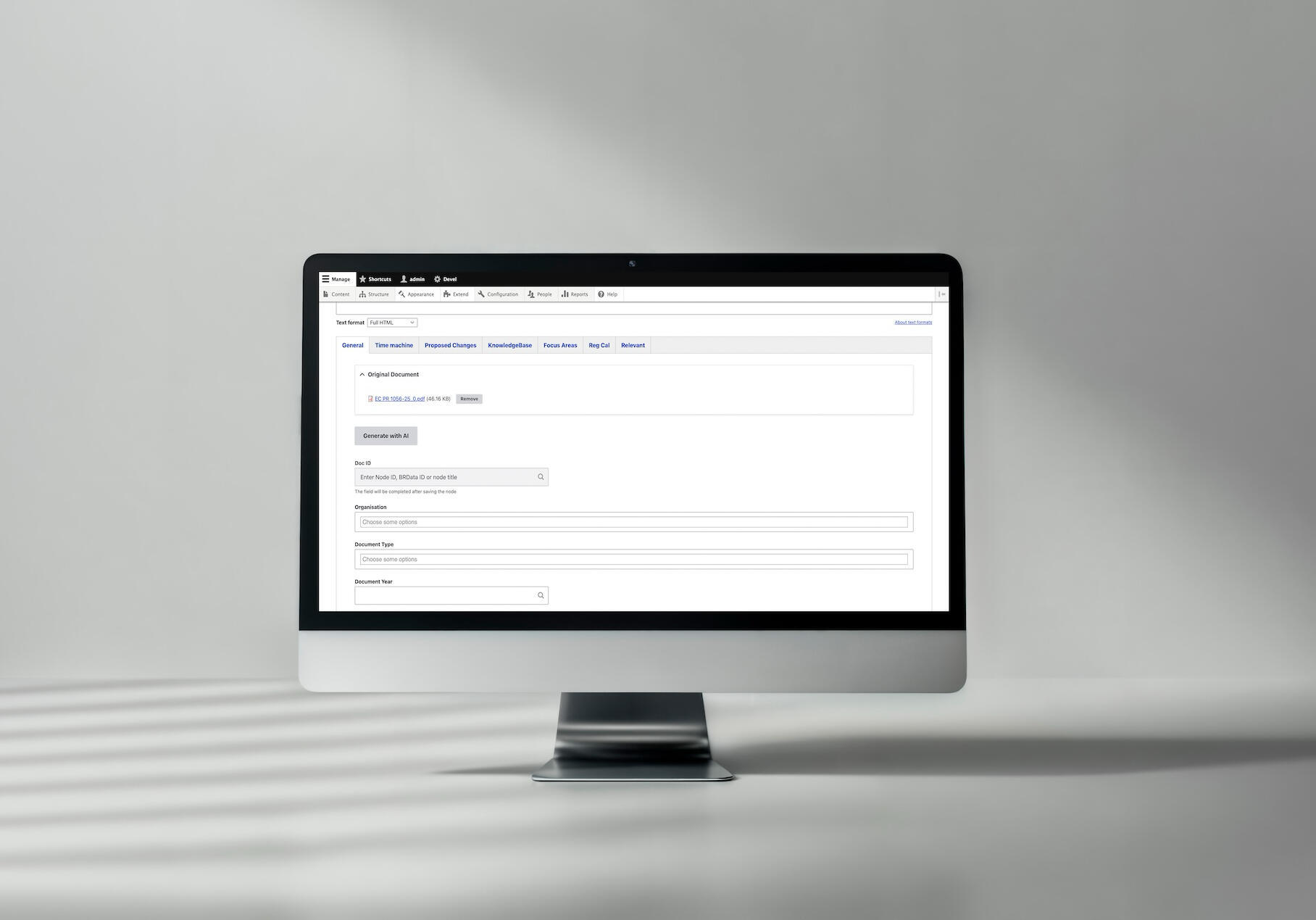
Kategoryzacja dokumentów z AI: jak Better Regulation skróciło czas pracy o 50%
Dla Better Regulation opracowaliśmy silnik kategoryzacji dokumentów oparty na sztucznej inteligencji, który zmniejsza nakład pracy redakcyjnej o połowę. Rozwiązanie automatyzuje ekstrakcję i klasyfikację pól w dokumentach prawnych, znacząco usprawniając cały proces. System wykorzystujący Drupal Automators i mechanizmy AI zamienia godziny ręcznego tagowania w szybki, stabilny i powtarzalny workflow, zapewniający przejrzystą strukturę oraz wygodne wyszukiwanie złożonych treści prawnych.
Kluczowe rezultaty
![]() 50% oszczędności czasu
50% oszczędności czasu
Czas potrzebny na przetwarzanie dokumentów skrócił się o połowę.
![]() Zaoszczędzona równowartość 1 etatu
Zaoszczędzona równowartość 1 etatu
Uwolniono potencjał redakcyjny na potrzeby rozwoju.
![]() Przetwarzanie trwające od 10 sekund do 2 minut
Przetwarzanie trwające od 10 sekund do 2 minut
Przetwarzanie AI vs minuty lub godziny ręcznej pracy.
![]() Obsługa od 2 do 350 stron dokumentów
Obsługa od 2 do 350 stron dokumentów
System obsługuje dokumenty wszystkich rozmiarów.
![]() Bardzo wysoka dokładność
Bardzo wysoka dokładność
Minimalna liczba poprawek, mniej niż 5% pól wymaga korekty.
![]() Zmniejszenie obciążenia poznawczego
Zmniejszenie obciążenia poznawczego
AI eliminuje konieczność czytania całego dokumentu.
O Better Regulation
Wyzwanie: przeciążony proces redakcyjny

Ręczne przetwarzanie dokumentów na dużą skalę
Przetwarzanie dokumentów prawnych dla platformy zgodności wymaga skrupulatnej dbałości o szczegóły. Każdy statut, rozporządzenie lub wytyczne musiały zostać przeczytane, sklasyfikowane i oznaczone w około 15 różnych polach – od typu dokumentu i jurysdykcji po rok uchwalenia i organizację.
Dla zespołu redakcyjnego Better Regulation ten ręczny proces stanowił poważne wąskie gardło operacyjne.

Dwustopniowy ręczny przepływ pracy
Przed wdrożeniem sztucznej inteligencji każdy dokument przechodził pracochłonny proces:
Krok 1: Czytanie i kategoryzacja dokumentów
Pierwszy redaktor:
- otrzymuje nowy dokument prawny (o długości od 2 do 350 stron),
- dokładnie czyta cały dokument, aby zrozumieć jego treść,
- ręcznie wyodrębnia kluczowe informacje: rodzaj dokumentu, tytuł, rok, jurysdykcję, organizację,
- odwołania do istniejących systemów taksonomicznych w celu zapewnienia spójnej kategoryzacji,
- wypełnia około 15 różnych pól w systemie zarządzania treścią.
Wymagany czas: od 15 minut do kilku godzin na dokument, w zależności od długości i złożoności.
Krok 2: Weryfikacja jakości
Drugi redaktor:
- sprawdza wszystkie kategoryzacje,
- weryfikuje poprawność przypisania pól,
- sprawdza zgodność ze standardami platformy.
Główne problemy
Rozwiązanie: proces redakcyjny wspomagany przez AI
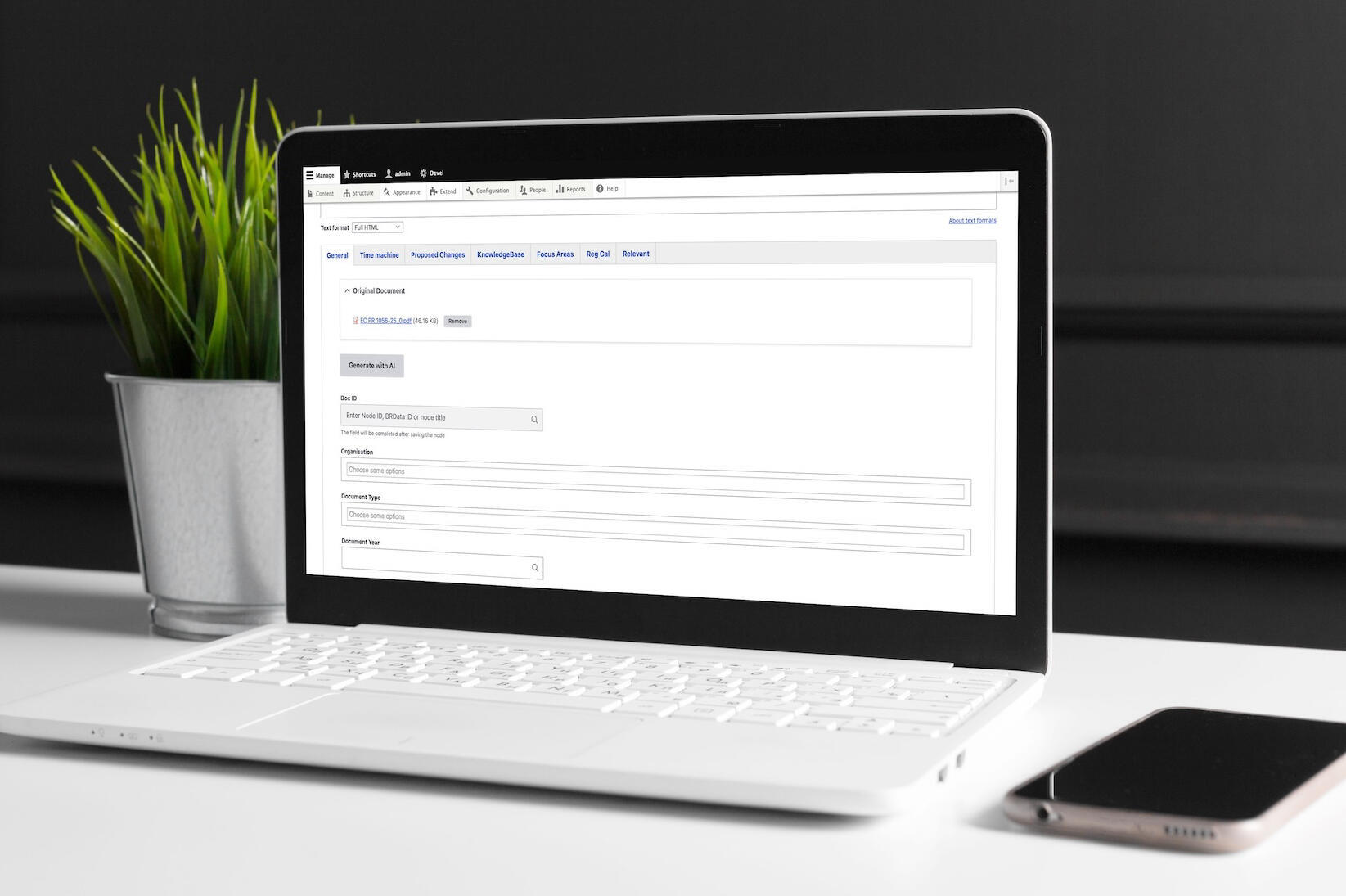
Podejście: wzbogacaj, nie zastępuj
Firma Droptica podeszła do tego wyzwania, badając, w jaki sposób sztuczna inteligencja może wzbogacić – a nie zastąpić – proces redakcyjny. Dzięki wspólnym sesjom odkrywczym z Better Regulation skupiliśmy się na jasnym celu: wyeliminowaniu czasochłonnych zadań związanych z ręcznym czytaniem i wprowadzaniem danych, przy jednoczesnym zachowaniu kontroli nad jakością i podejmowaniem decyzji przez redaktorów.
Filozofia była prosta: niech sztuczna inteligencja zajmuje się żmudną, powtarzalną pracą, a ludzie – oceną, weryfikacją i kontrolą jakości.
Faza odkrywania i testowania
Zamiast od razu przystępować do wdrażania, zespół Droptica przeprowadził dokładne testy różnych podejść, aby upewnić się, że rozwiązanie będzie niezawodne, dokładne i gotowe do użycia na produkcji.

Metody przetwarzania plików PDF
Pliki PDF o charakterze prawnym są niezwykle złożone. Często zawierają:
- wiele kolumn i skomplikowane układy,
- nagłówki, stopki i numery stron w całym dokumencie,
- osadzone obrazy i grafiki,
- tabele i dane strukturalne,
- różne czcionki i style formatowania.
Oceniliśmy wiele metod wyodrębniania czystego, użytecznego tekstu:
- Bezpośrednie przesyłanie plików PDF do API ChatGPT – ujawniło ograniczenia związane ze złożonym formatowaniem i rozmiarem plików.
- Tradycyjne biblioteki do analizowania plików PDF – miały problemy z niespójnymi strukturami dokumentów i generowały nieczytelne wyniki.
- Unstructured.io – wyłonił się jako zdecydowany zwycięzca.
Wybór Unstructured.io okazał się kluczowy. Zespół stwierdził, że nie ma kontroli nad konstrukcją plików PDF – dokumenty prawne często zawierają liczne znaczniki formatowania i metadane, które mogą “zatykać” okno kontekstowe i dezorientować sztuczną inteligencję. Dzięki Unstructured.io można je odfiltrować już na etapie ekstrakcji. Zespół zauważył również znacznie większą dokładność i szybsze przetwarzanie w porównaniu z innymi metodami.
Wybór modelu językowego
Zespół przetestował wiele dużych modeli językowych, oceniając je według trzech kluczowych kryteriów:
- Dokładność: czy model potrafił poprawnie zidentyfikować i sklasyfikować informacje zawarte w dokumencie?
- Szybkość: jak szybko może przetwarzać dokumenty o objętości od 2 do 350 stron?
- Koszt: jaki był koszt tokenu per dokument przy oczekiwanych wolumenach?
Po przeprowadzeniu szeroko zakrojonych testów z wykorzystaniem rzeczywistych dokumentów Better Regulation zdecydowaliśmy się na model GPT-4o-mini jako najlepiej dopasowany do aktualnych potrzeb projektu. Jednocześnie proces rozwoju pozostaje otwarty na testowanie innych modeli. Jeśli w przyszłości pojawią się rozwiązania oferujące lepszy balans między jakością, wydajnością i możliwościami, zastosowany model może zostać zmieniony. Na obecnym etapie GPT-4o-mini zapewnia odpowiednią równowagę między szybkością, dokładnością oraz wystarczająco dużym oknem kontekstowym (128 tys. tokenów), umożliwiającym pracę nawet z najdłuższymi dokumentami.
Inżynieria promptów
Znaczny wysiłek włożono w opracowanie promptów, które w niezawodny sposób wyodrębniałyby i kategoryzowały informacje. Ten iteracyjny proces obejmował:
- Określenie jasnych, jednoznacznych instrukcji dotyczących wyodrębniania pól.
- Dostarczenie kompletnych list taksonomicznych w kontekście podpowiedzi.
- Określenie dokładnych formatów wyjściowych JSON w celu zapewnienia spójnego parsowania.
- Dodanie reguł walidacji i obsługi przypadków skrajnych.
- Testowanie z wykorzystaniem setek rzeczywistych dokumentów w celu udoskonalenia dokładności.
Jak to działa?
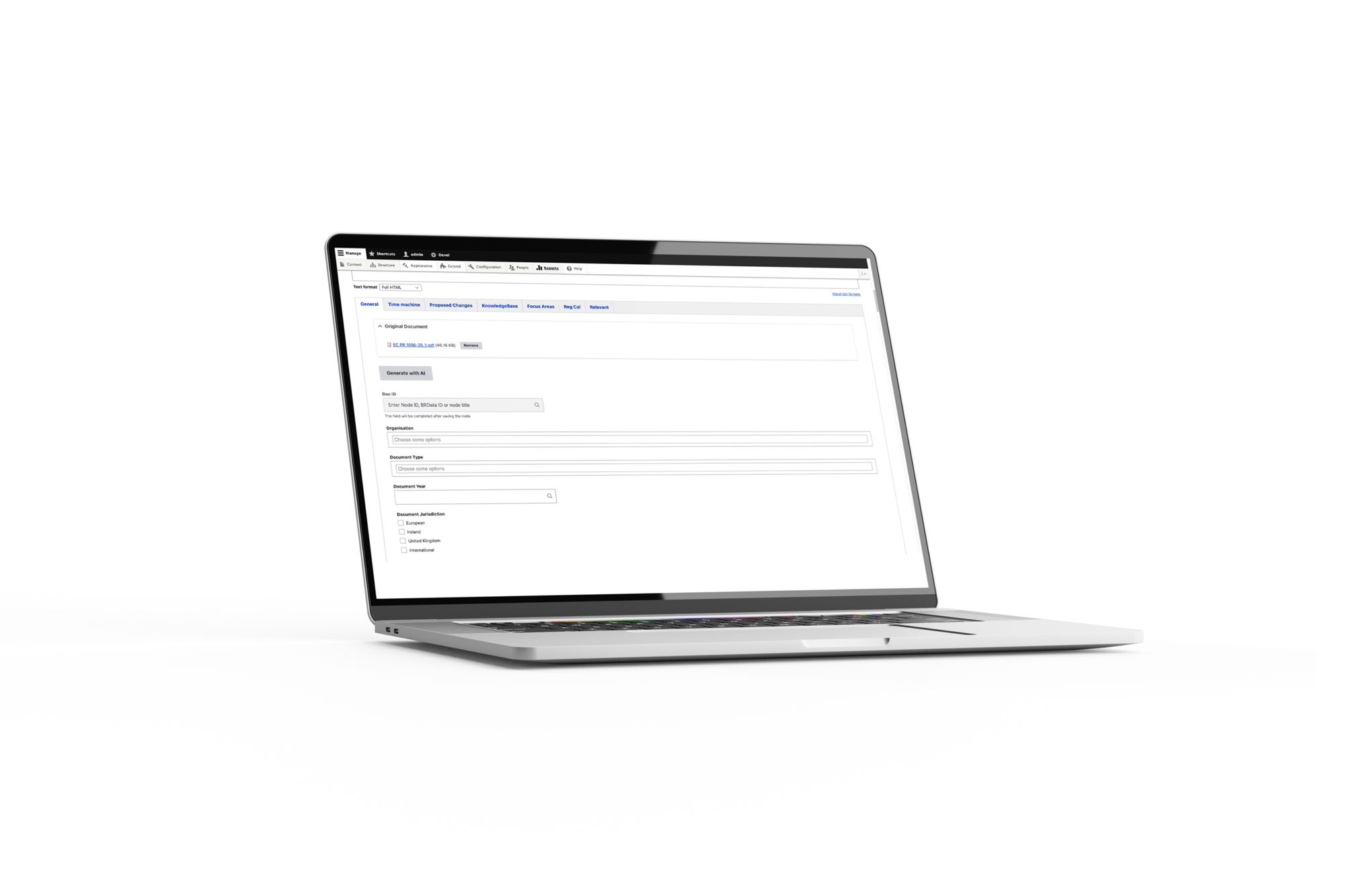
Funkcja autouzupełniania
Rozwiązanie płynnie integruje się z istniejącym procesem redakcyjnym Better Regulation opartym na Drupal 11.
Z perspektywy redaktora:
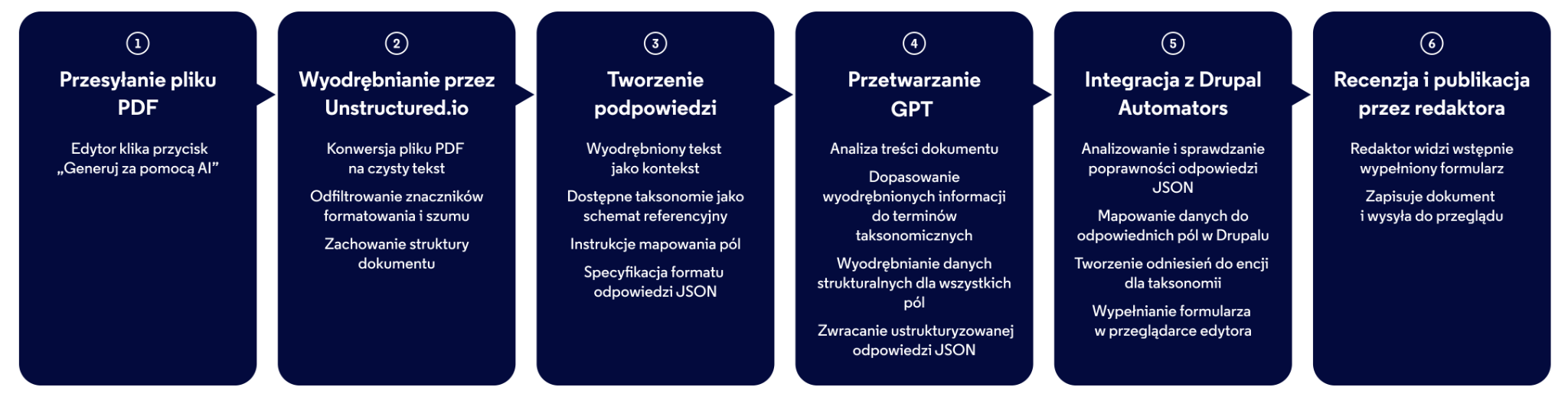
- Przesyłanie pliku PDF: redaktor tworzy nowy wpis dokumentu i przesyła plik PDF do pola „Oryginalny dokument”.
- Wybranie opcji „Generuj za pomocą AI”: jedno kliknięcie przycisku uruchamia przetwarzanie AI.
- Krótkie oczekiwanie: od 10 sekund do 2 minut w zależności od rozmiaru dokumentu (nie ma potrzeby odświeżania strony).
- Dostosowanie w razie potrzeby: redaktor może zmodyfikować dowolne pole przed zapisaniem.
- Zapisanie i publikacja: dokument jest gotowy do umieszczenia na platformie.
Transformacja doświadczenia:
- Wcześniej: od 15 minut do kilku godzin czytania i ręcznego wprowadzania danych.
- Teraz: wystarczy kliknąć przycisk, chwilę poczekać i wysłać recenzję.
Redaktorzy zachowują kontrolę. Mogą modyfikować dowolne automatycznie wypełnione pola przed zapisaniem. Pozwala to zachować standardy jakości przy jednoczesnym wyeliminowaniu żmudnej pracy.
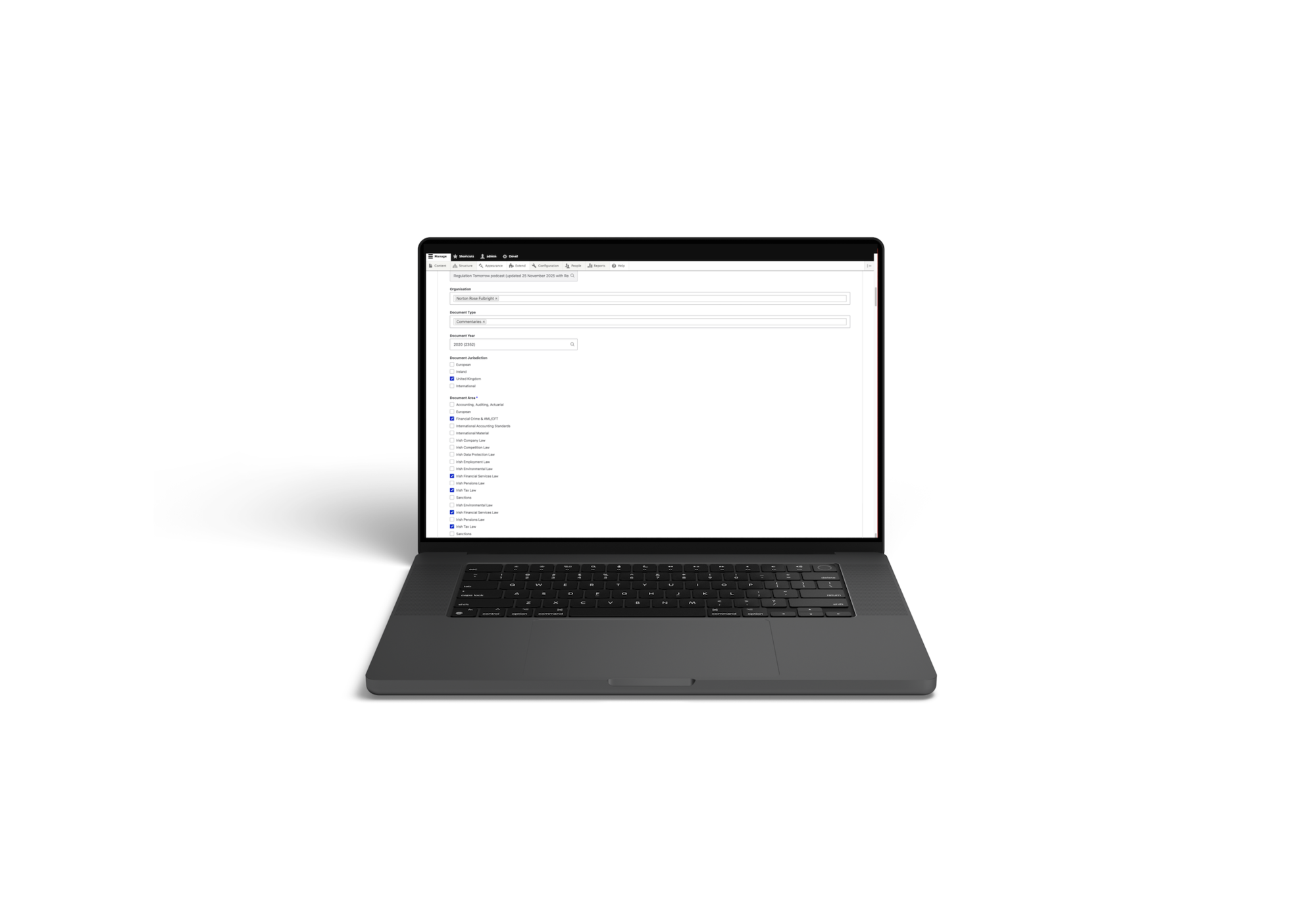
Pola wypełniane automatycznie przez AI
System wypełnia około 15 pól, w tym:
Pola tekstowe:
- Tytuł – wyodrębniony i oczyszczony tytuł dokumentu.
- Treść/podsumowanie – kluczowe fragmenty treści wyodrębnione z dokumentu.
Odniesienia taksonomiczne:
- Typ dokumentu – ustawa, rozporządzenie, wytyczne, kodeks itp.
- Organizacja – organ wydający lub organ regulacyjny.
- Obszar dokumentu – klasyfikacja tematyczna.
- Ustawodawstwo dotyczące dokumentu – powiązane ramy prawne.
Odniesienia do podmiotów:
- Jurysdykcja – Wielka Brytania, Irlandia, UE (może być więcej niż jedna) etc.
Pola daty:
- Rok – kiedy dokument został uchwalony lub opublikowany.
Pola adresu URL:
- Źródło URL – oficjalna lokalizacja publikacji.
Oraz dodatkowe pola metadanych specyficzne dla modelu treści Better Regulation.
Innowacja techniczna: inteligentne mapowanie taksonomii
Kluczowym osiągnięciem technicznym jest sposób, w jaki system obsługuje odniesienia taksonomiczne w Drupalu. Sztuczna inteligencja nie tylko wyodrębnia tekst, ale także inteligentnie mapuje wyodrębnione informacje do istniejących terminów taksonomicznych w bazie danych Drupala.
Oto, jak to działa:
- Wprowadzanie kontekstu: system zawiera pełną listę dostępnych terminów taksonomicznych dla każdego pola w poleceniu wysyłanym do sztucznej inteligencji.
- Dopasowanie semantyczne: AI analizuje treść dokumentu i dopasowuje ją do tych terminów na podstawie znaczenia, a nie tylko słów kluczowych.
- Zwrot identyfikatora: zwraca nie tylko dopasowane nazwy terminów, ale także konkretne identyfikatory encji w Drupalu.
- Tworzenie odniesień do encji: moduł Drupal Automators tworzy następnie odpowiednie odniesienia do encji przy użyciu tych identyfikatorów
Takie podejście zapewnia:
- Płynną integrację z istniejącą architekturą treści Better Regulation.
- Brak „osieroconych” terminów lub niespójności danych.
- Prawidłowe relacje między dokumentami a taksonomiami.
- Możliwość utrzymania struktury danych w miarę ewolucji taksonomii.
Architektura techniczna
Rozwiązanie opiera się na solidnej, gotowej do użycia na produkcji architekturze zaprojektowanej z myślą o niezawodności i skalowalności.
Stos technologiczny:
Drupal 11 – platforma zarządzania treścią.
Drupal Automators (moduł contrib) – koordynuje przepływy pracy AI i zarządza logiką przetwarzania.
Unstructured.io (Extracture) – ekstrakcja i czyszczenie tekstu z plików PDF, samodzielnie hostowane w celu zapewnienia kontroli.
GPT-4o-mini (OpenAI) – model językowy do analizy i kategoryzacji tekstu.
RabbitMQ – kolejka komunikatów do przetwarzania w tle (używana do funkcji podsumowania).
Watchdog – kompleksowe logowanie i monitorowanie błędów.
Przebieg przetwarzania:
Kluczowe decyzje techniczne
| Wyzwanie | Rozwiązanie | Uzasadnienie |
|---|---|---|
| Złożone formatowanie plików PDF | Unstructured.io | Doskonałe filtrowanie artefaktów PDF, lepsza obsługa tabel i układów wielokolumnowych, wyższa dokładność ekstrakcji. |
| Wybór modelu | GPT-4o-mini | Optymalna równowaga między szybkością, dokładnością i kosztami, duże okno kontekstowe (128 tys. tokenów) obsługuje najdłuższe dokumenty. |
| Format wyjściowy | Strukturalny JSON ze schematem | Zapewnia spójne, możliwe do analizy odpowiedzi; weryfikuje zgodność z oczekiwanymi typami pól. |
| Dopasowanie taksonomii | Pełne listy taksonomii zawarte w podpowiedzi | Sztuczna inteligencja może dopasowywać semantycznie, a nie na podstawie dokładnych słów kluczowych; zwraca właściwe identyfikatory podmiotów. |
| Doświadczenie użytkownika | Synchroniczne przetwarzanie na żądanie | Redaktorzy widzą natychmiastowe wyniki; mogą je zweryfikować przed zapisaniem; nie muszą czekać na zadania w tle. |
| Duże dokumenty | Łagodna degradacja | Dokumenty przekraczające limity tokenów są oznaczane do ręcznej weryfikacji z wyraźnymi komunikatami o błędach. |
| Niezawodność | Kompleksowe rejestrowanie błędów | Wszystkie awarie są rejestrowane w Watchdog wraz z kontekstem; pulpit administracyjny pokazuje status przetwarzania. |
Wybór technologii
Sztuczna inteligencja wspomaga, ale nie zastępuje ludzkiej oceny. To wielopoziomowe podejście zapewnia utrzymanie wysokich standardów Better Regulation przy jednoczesnym uzyskaniu znacznych korzyści w zakresie wydajności.
Rezultaty: transformacyjny wzrost wydajności
50% oszczędności czasu w przetwarzaniu dokumentów
Najbardziej znaczącym i natychmiastowo mierzalnym rezultatem jest radykalne skrócenie czasu potrzebnego na przetwarzanie dokumentów.
Better Regulation pozwala uzyskać 50% ogólnej oszczędności czasu w całym procesie pozyskiwania, kategoryzacji, przeglądu i publikacji dokumentów.
Uwolnienie wydajności odpowiadającej jednemu etatowi
To, co kiedyś pochłaniało cały dzień pracy redaktora, teraz zajmuje godzinę. Sztuczna inteligencja realizuje żmudną część zadania – czytanie i wyodrębnianie informacji – podczas podczas gdy edytorzy mogą skupić się na weryfikacji i kontroli jakości.
Oznacza to uwolnienie równowartości jednego pełnego etatu (1 FTE) w zakresie zdolności redakcyjnych, które można przeznaczyć na prace o większej wartości.
Skalowalność bez wzrostu liczby pracowników
Być może najważniejsze dla działalności Better Regulation jest to, że rozwiązanie AI zapewnia skalowalność, która wcześniej wymagałaby proporcjonalnego wzrostu liczby pracowników.
Innowacje techniczne: sukces Drupal + AI
Projekt ten pokazuje możliwości nowoczesnego Drupala w zakresie zaawansowanej integracji AI.