
Jakich narzędzi do monitorowania działania serwerów warto używać?

Monitorowanie serwerów jest złożonym procesem monitorowania całej infrastruktury związanej z serwerami i ich zależnościami, w celu analizy wykorzystania zasobów systemowych oraz ich optymalizacji dla zapewnienia usług użytkownikom końcowym. Bez wątpienia jest to jeden z elementów kluczowych dla sprawnego działania infrastruktur. Dlatego wybór odpowiedniego narzędzia ma dla każdej firmy istotne znaczenie.
Dlaczego należy monitorować działanie serwera?
Monitoring jest w świecie IT standardem, ponieważ pozwala na utrzymanie serwerów przedsiębiorstwa w optymalnej kondycji. Sam proces monitorowania wydajności serwera jest dość prosty - opiera się na regularnym gromadzeniu danych serwera i analizie ich w czasie rzeczywistym lub historycznym. Dzięki temu mamy pewność, że serwery działają optymalnie, spełniając w ten sposób zamierzoną funkcję.
Monitorować można prawie wszystko, m.in. kontrolę wydajności procesora, zużycia pamięci, przepustowości sieci i przestrzeni dyskowej, a także identyfikację problemów związanych z użytkowaniem serwerów. Jednak sama wiedza na temat monitorowania serwera nie wystarczy. Konieczna jest świadomość, dlaczego jest to tak ważny element bezpieczeństwa organizacji. Zadaniem monitoringu jest także informowanie o awariach i problemach z wydajnością oraz rozwiązywanie problemów z odpowiednim wyprzedzeniem. W praktyce oznacza to, że awaria lub anomalie wykrywane są na tyle szybko, że nie dochodzi do zatrzymania usługi lub aplikacji czy pracy całego przedsiębiorstwa. W efekcie infrastruktura serwerowa firmy działa właściwie i stabilnie, a organizacja nie ponosi strat spowodowanych przez długie przerwy w działaniu systemu.
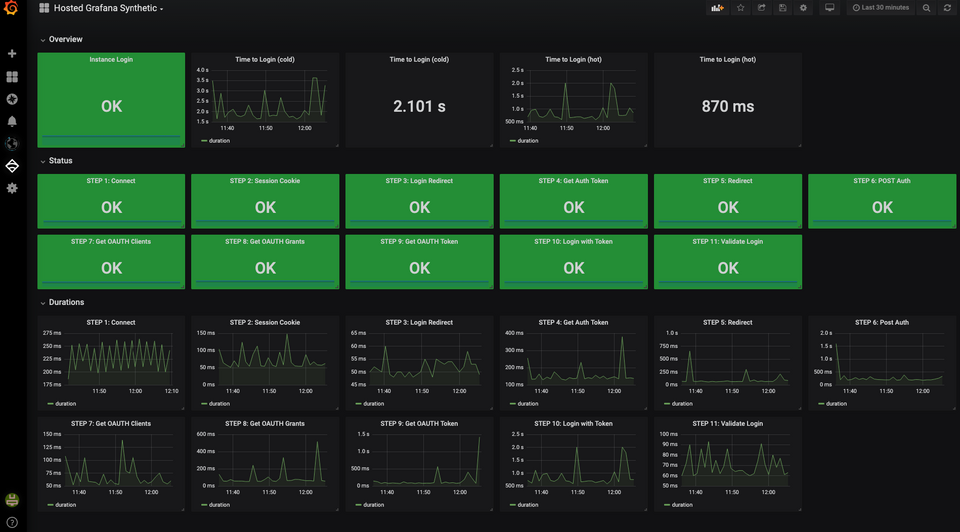
Źródło: Grafana
Skąd wiadomo, że serwer nie działa?
Właściwe i nieprzerwane monitorowanie serwera zapewnia, że serwer działa i jest odpowiednio zoptymalizowany. Ponadto pozwala zminimalizować ryzyko wszelkich przerw w działaniu systemu, a kiedy dojdzie do awarii – dokonać precyzyjnej analizy procesów, która doprowadzi do szybkiej naprawy. Nigdy jednak nie można przewidzieć, co się wydarzy, a może stać się wszystko - aplikacja przestanie działać, zabraknie zasobów na serwerze, wystąpi problem z dostępnością usług od ISP itp. Wówczas informacja o niedostępności strony internetowej lub innej usługi powinna być dostarczona przez system monitoringu, a nie przez szefa firmy lub użytkownika końcowego. Aby uniknąć takich sytuacji, należy wdrożyć odpowiednie narzędzie do monitoringu, które pomoże zapobiec ewentualnym problemom i awariom, informując o tym administratorów lub odpowiedzialne za to działy.
1. Zabbix
Jest to nieoficjalny lider w dziedzinie monitoringu. Początki tego narzędzia sięgają 1998 roku, a jego twórcą i założycielem jest Alexei Vladishev, który cały czas bardzo aktywnie rozwija swój produkt. Zabbix jest rozwiązaniem typu open source, opartym na licencji GPL (General Public License), dzięki czemu jest darmowy do użytku komercyjnego i niekomercyjnego. Do tej pory program doczekał się już kilkunastu wersji, a aktualnie najbardziej popularną jest wersja 5.0 LTS, z 5-letnim wsparciem długoterminowym, która idealnie nadaje się na środowisko produkcyjne. Następne wydanie zostało oznaczone numerem 5.4, kilka dni temu pojawiła się wersja 6.0 LTS, a roadmap informuje o planach kolejnych aż do 7.0 LTS włącznie. Każda nowa wersja zawiera szereg nowych zmian, uwzględniających potrzeby i wymagania zmieniającego się rynku IT. Wersja 6.0 wprowadza nowe funkcjonalności, wśród których należy wyróżnić: monitorowanie klastrów Kubernetes, wykrywanie anomalii na podstawie uczenia maszynowego oraz rozbudowę monitoringu pod kątem biznesowym.
System Zabbix umożliwia monitorowanie urządzeń wspierających technologię SNMP, IPMI oraz protokoły ICMP, TCP, UDP, HTTP, a także stworzenie własnych pozycji do monitorowania. Monitoring sprzętowy obejmuje komputery stacjonarne, serwery fizyczne, serwery wirtualne, dyski sieciowe, switche, routery, środowiska Windows i Linux oraz wiele innych.
Funkcjonalności Zabbixa są ogromne i umożliwiają monitorowanie przykładowo:
- obciążenia procesorów, kart sieciowych i pamięci, ilości miejsca na dyskach twardych,
- stron internetowych i aplikacji webowych,
- standardowych protokołów sieciowych: SMTP, ICMP, SSH, TELNET, IPMI, JPX, HTTP/ HTTPS,
- rozproszonych lokalizacji (oddziały lub filie),
- ważności certyfikatów SSL na stronach www,
- temperatury poszczególnych podzespołów,
- poprawnego wykonania zapytania SQL.
Do monitorowania wymienionych zasobów możemy wykorzystać gotowe, darmowe szablony lub stworzyć własne.
Architektura Zabbixa składa się z kilku elementów. Najważniejszym z nich jest Zabbix Server, który odpowiada na odbiór, agregację i przetwarzanie danych, a także generowanie na ich podstawie zdarzeń i wykrywanie anomalii. Dla wybranych incydentów można wysyłać alerty w formie powiadomienia SMS, mail lub z wykorzystaniem Webhook do integracji z najpopularniejszym systemami helpdesk, chatami i komunikatorami (np. Microsoft Teams, Messenger). Kolejnym elementem jest Zabbix Agent, który zbiera metryki lokalnie z systemu operacyjnego. Ten daemon, dostępny na systemach UNIX i Windows, charakteryzuje się niskim zużyciem zasobów i może działać w trybie pasywnym i aktywnym. W trybie pasywnym, agent przetwarza żądanie z serwera z listą parametrów, które powinien kontrolować i zwraca do niego zebrane dane. Z kolei agent w trybie aktywnym pierwszy nawiązuje komunikację z serwerem i regularnie wysyła do niego dane. Ten tryb przydaje się, gdy serwer z jakiegoś powodu nie może bezpośrednio nawiązać komunikacji z agentem. Agent, dzięki wbudowanym liczym szablonom, potrafi sprawdzać wiele parametrów bez dodatkowej konfiguracji. Opcjonalnym elementem, który możemy wykorzystać jest serwer Zabbix Proxy, który pośredniczy w komunikacji między Zabbix Agentem a Zabbix Server. Takie rozwiązanie warto zastosować w infrastrukturze rozproszonej w wielu lokalizacjach, np. oddziałach firmy, lokalizacjach charakteryzujących się słabym łączem lub miejscach bez lokalnych administratorów.
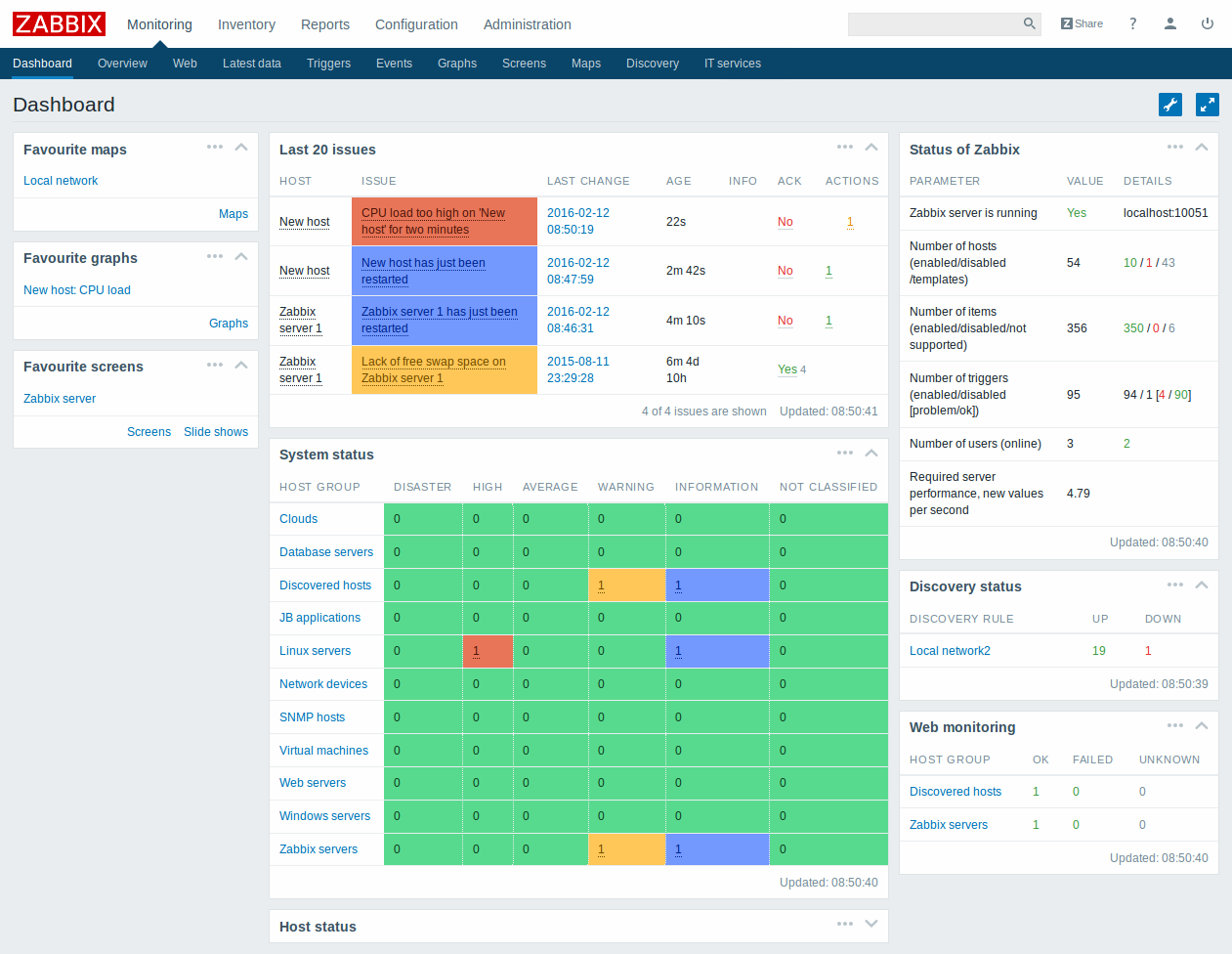
Źródło: Zabbix
W swojej ofercie Zabbix posiada także bogaty zestaw integracji z różnymi systemami i platformami. Spośród ogromnej ich liczby, wynoszącej ponad 500 narzędzi, należy wyróżnić integracje z:
- największymi dostawcami usług chmurowych (np. AWS, Azure, Google),
- kontenerami (np. Docker, LXC),
- systemami ticketowymi (np. Jira, OTRS),
- systemami zarządzania konfiguracją (np. Ansible, Puppet),
- systemami przesyłania wiadomości (np. PagerDuty, Slack).
Dużą zaletą Zabbixa jest posiadanie społeczności oraz możliwość pozyskiwania wiedzy za pomocą wielu kanałów wsparcia (m.in. Support System, Telegram, Discord, Zabbix Forum). Dla bardziej wymagających klientów, producent przygotował 5 różnych poziomów wsparcia, w zależności od oczekiwanych potrzeb.
2. Nagios XI
Nagios XI jest systemem do monitorowania infrastruktury korporacyjnej, wywodzącym się ze świata open source. Oprogramowanie to powstało na bazie silnika Nagios Core, które z czasem zostało wzbogacone o funkcje dostosowane dla klientów biznesowych. Nagios Core nadal pozostał narzędziem darmowym, rozwijanym zgodnie z licencją GNU GPL v2, a Nagios XI przekształcił się w pełni komercyjne rozwiązanie.
Architektura Nagios XI oparta jest na rodzinie systemów Linux/Unix z dedykowanymi do instalacji systemami: CentOS, Redhat Enterprise Linux, Ubuntu i Debian. Jednak wdrożenie narzędzia można również przeprowadzić w systemie Windows, z wykorzystaniem środowiska wirtualnego VMware Workstation Player lub Hyper-V. Opisywane narzędzie ma nieograniczone możliwości i jest wykorzystywane do kompleksowego monitorowania infrastruktury. Oprócz monitoringu krytycznych elementów infrastruktury, tj. urządzeń i protokołów sieciowych, aplikacji, systemów operacyjnych, baz danych, Nagios XI oferuje monitoring zasobów obliczeniowych, kontroli parametrów środowiskowych czy IoT. Klienci mają do wyboru dwie wersje produktu: Standard Edition i Enterprise Edition.
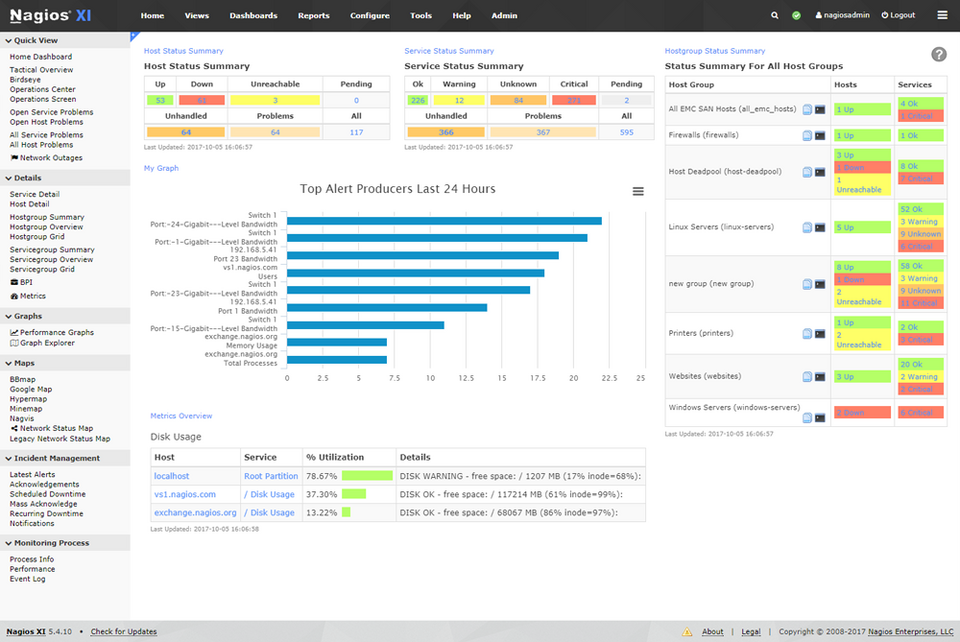
Źrodło: Nagios
Pomimo tego, że Nagios XI jest narzędziem komercyjnym, producent oferuje bezpłatną licencję do 7 węzłów, która może być niezwykle korzystna do użytku domowego, na przykład:
- monitorowanie kondycji domowego serwera plików (storage, temperatura),
- monitorowanie statusu drukarki (poziomu atramentu i papieru w drukarce), routera lub switcha,
- wykorzystanie w inteligentnym domu razem z Raspberry Pi i zbieranie danych z czujników i przekazywanie danych na temat np. poziomu wód gruntowych, światła słonecznego, a nawet kwasowości (pH) gleby oraz alertów o stanie bramy garażowej na podstawie pory dnia.
Obsługa narzędzia odbywa się z poziomu przeglądarki, a sam interfejs jest prosty i czytelny. Jednak na tym polu jest miejsce do poprawy, ponieważ UI wyraźnie odbiega od aktualnych trendów.
Natomiast kreatory konfiguracji Nagios XI są intuicyjne i bardzo proste w użyciu i nie wymagają złożonej wiedzy na temat procesu monitorowania infrastruktury IT. Zebrane dane wykorzystywane są do wykresów, dzienników zdarzeń, statystyk, analizy trendów oraz planowania zasobów i wydajności. Wszelkie alerty, na temat m.in. niedostępności usług czy przekroczenia krytycznych wartości, są wysyłane za pośrednictwem wiadomości e-mail i SMS.
Możliwości systemu można rozszerzyć dzięki szerokiej ofercie dodatków firm trzecich udostępnianych w ramach licencji GPL. Nagios XI posiada również rozszerzalną architekturę z możliwością użycia dowolnego preferowanego języka programowania. System udostępnia wiele interfejsów API, co zapewnia prostą integrację z aplikacjami wewnętrznymi i zewnętrznymi.
3. Prometheus
Prometheus, określany jako zestaw narzędzi do monitorowania i ostrzegania systemów typu open source, został stworzony w 2012 roku przez byłych pracowników Google. Początkowo był przeznaczony do monitorowania tylko skonteneryzowanych środowisk, ale z czasem rozszerzył swoje możliwości na aplikacje, serwery, bazy danych oraz wirtualne maszyny. Aktualnie system jest intensywnie rozwijany w środowiskach cloudowych.
Prometheus jest niezależnym narzędziem open source, aktywnie wspieranym przez programistyczną społeczność, a wszystkie jego komponenty są dostępne na licencji Apache 2 w serwisie GitHub. Nie przeszkadza to jednak dużym firmom w wykorzystywaniu tego systemu jako kluczowego elementu infrastruktury. Wśród klientów można wyróżnić m.in. DigitalOcean, Docker, Showmax czy SoundCloud. Dodatkowo o wielkości narzędzia świadczy fakt, że Prometheus dołączył do Cloud Native Computing Foundation, jako drugi projekt po Kubernetes. Takie wyróżnienie otrzymują tylko dostawcy najszybciej rozwijających się projektów open source.
Kluczowym elementem działania tego narzędzia są metryki, które charakteryzują daną aplikację lub instancję i dostarczają o nich informacje. Biblioteki klienckie dla Prometheusa oferują wbudowane cztery główne typy metryk, które mogą przekazywać różne dane, np. ilość requestów i błędów HTTP (metryka Counter), czas odpowiedzi (Histogram), użycie pamięci (Gauge), a także ilość aktywnych użytkowników (Summary). Każdej metryce przypisywana jest nazwa, do której można się odwoływać, wraz z opcjonalnymi parami klucz-wartość, zwanymi etykietami. Prometheus zbiera metryki w oparciu o metody push i pull. W pierwszym przypadku to monitorowana aplikacja jest odpowiedzialna za wysyłanie własnych metryk do systemu monitorowania przez Pushgateway. Natomiast w metodzie pull, aplikacja jest pasywna i przygotowuje tylko swoje metryki w formie endpointu, a Prometheus na podstawie reguł sam decyduje, kiedy je pobrać. Opisywane narzędzie do monitorowania działania serwerów posiada wydajną wbudowaną bazę danych szeregów czasowych, więc informacje o metrykach są przechowywane wraz ze znacznikiem czasu, w którym zostały zarejestrowane.
Jednym z filarów narzędzia jest język zapytań - Prometheus Query Language (PromQL) - wykorzystywany do odpytywania i agregowania danych monitorowania w czasie rzeczywistym przy użyciu różnych operatorów i funkcji. Do automatyzacji monitoringu wykorzystywana jest niezależna aplikacja Alertmanager, która generuje i wysyła alerty po zaobserwowaniu określonych warunków. Prometheus udostępnia bogaty zestaw eksporterów, w celu monitorowania praktycznie wszystkiego, ale sam nie posiada możliwości wizualizacji zebranych danych. Tu z pomocą przychodzi Grafana, w której dashboardy łączą się ze źródłami danych w celu wizualizacji metryk niemal w czasie rzeczywistym. Specjaliści obu rozwiązań intensywnie ze sobą współpracują, rozwijając zaawansowaną już integrację z Prometheusem w Grafanie i zapewniając klientom Grafana dostęp do potrzebnych im funkcji Prometheusa.
Okazałe efekty przynosi także współpraca z największym dostawcą usług chmurowych - Amazon Web Services. W zeszłym roku została uruchomiona usługa Amazon Managed Service for Prometheus. Jest ona w pełni kompatybilna z Prometheusem, charakteryzuje się wysoką dostępnością, automatycznie skaluje się wraz ze wzrostem potrzeb oraz zawiera pakiet zgodności i zabezpieczeń AWS. Usługa umożliwia zbieranie metryk ze środowisk Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS) i Amazon Elastic Kubernetes Service (Amazon EKS).
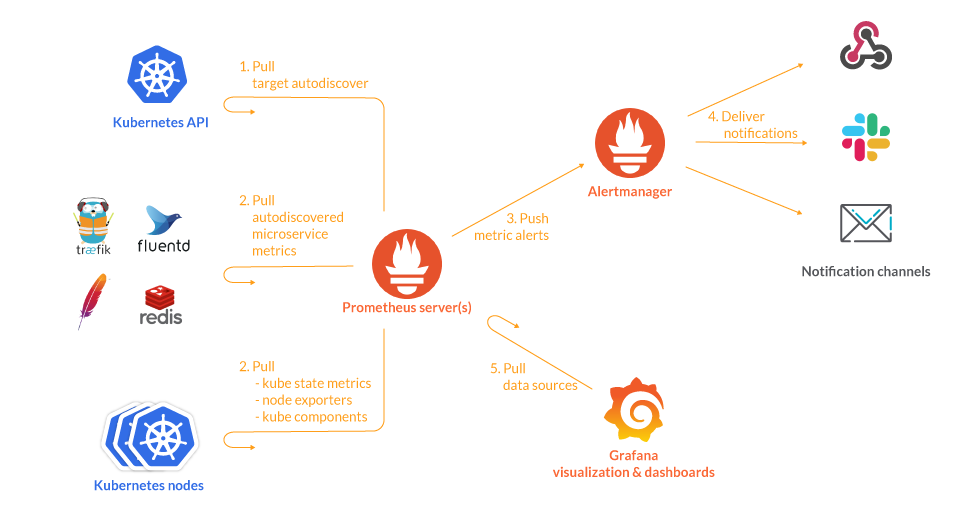
Źródło: Sysdig
4. Datadog
Jest to kompletne rozwiązanie do monitoringu oraz analizy infrastruktury i aplikacji. Narzędzie umożliwia wizualizację zebranych danych i wysyłanie powiadomień o problemach technicznych, pomagając administratorom wykrywać krytyczne błędy i w pełni kontrolować systemy IT. Datadog działa w modelu SaaS i wykorzystywany jest w infrastrukturze umieszczonej w chmurze, środowisku hybrydowym lub lokalnym. Swoim zakresem obejmuje tradycyjny monitoring infrastruktury, monitoring wydajności aplikacji w czasie rzeczywistym, analizę aktywności sieciowej i ruchu, monitorowanie wydajności baz danych, DNS oraz przepustowości.
Datadog agreguje metryki i zdarzenia w jednym miejscu, umożliwia ich łatwą analizę i wyróżnia aktualne wartości krytycznych wskaźników KPI, SLO i SLA. Wykorzystywane są do tego przejrzyste i dynamiczne dashboardy, bez konieczności stosowania języka zapytań ani kodowania, z bogatą ofertą bibliotek formuł, funkcji i widgetów typu drag-and-drop.
Rozwiązywanie problemów, alertów i tworzenie wykresów umożliwia ponad 500 integracji, wśród których można wyróżnić współpracę z Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, OpenStack czy Red Hat OpenShift. Oprócz tego Datadog posiada zgodność z metrykami coraz popularniejszych narzędzi DevOps - Kubernetes i Prometheus. Zaletą systemu jest również zarządzanie dziennikami. Zbieranie logów ze wszystkich usług, aplikacji i platform, ich przeszukiwanie i filtrowanie, automatyczne tagowanie, wizualizacja i ostrzeganie o danych dziennika - to wszystko prowadzi do bardziej efektywniejszego monitoringu. Do wykrywania wszelkich anomalii zastosowano rozwiązania oparte na sztucznej inteligencji. Alerty o problemach w środowisku wysyłane są za pośrednictwem wiadomości e-mail, PagerDuty, Slack, Hangouts Chat i Microsoft Teams. O wielkości systemu Datadog świadczy wielkość jego klientów. Intensywnie używają go takie marki jak m.in. Samsung, Siemens, Lego System, Sony oraz Lufthansa Systems.
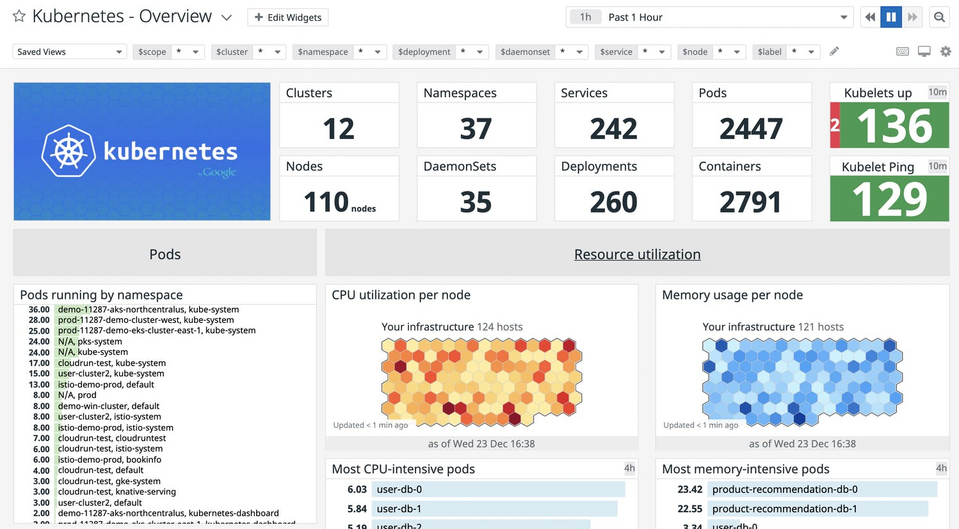
Źródło: Datadog
5. Sematext
Sematext jest rozwiązaniem do monitorowania wydajności infrastruktury i aplikacji oraz zarządzania logami. Narzędzie można używać w wersji Cloud lub Enterprise. Podczas gdy Sematext Cloud to w pełni zarządzana usługa SaaS, Sematext Enterprise jest gotową paczką do pobrania i uruchomienia w swojej infrastrukturze. Obie wersje zawierają taki sam pakiet usług i umożliwiają pełną widoczność infrastruktury, monitorowanie kontenerów, baz danych, kontrolę wydajności aplikacji, zarządzanie logami oraz alertowanie. Coraz popularniejsza wersja chmurowa charakteryzuje się wysoką dostępnością, skalowalnością i wydajnością oraz monitorowaniem usług w chmurach prywatnych, publicznych i hybrydowych. Do rozpoczęcia pracy na hostach wymagany jest agent, który automatycznie rozpoznaje elementy do monitorowania. Hostami mogą być dowolne maszyny fizyczne, systemy w środowiskach wirtualnych, kontenery (Docker, ECS) czy klastry (EKS, Kubernetes).
Sematext oferuje w pełni zarządzane usługi Elasticsearch i Kibana, bez konieczności utrzymywania kosztownych specjalistów i infrastruktury, dzięki czemu oszczędzony zostaje czas przeznaczony na konserwację systemu. Interfejs i obsługa dashboardu jest przyjazna dla użytkownika i pozwala:
- filtrować oraz analizować metryki i zdarzenia,
- wyszukiwać dane,
- tworzyć niestandardowe pulpity nawigacyjne i raporty,
- generować niestandardowe alerty w oparciu o wydajność usługi,
- rozwiązywać problemy z wydajnością
- oraz wykrywać trendy i wzorce.
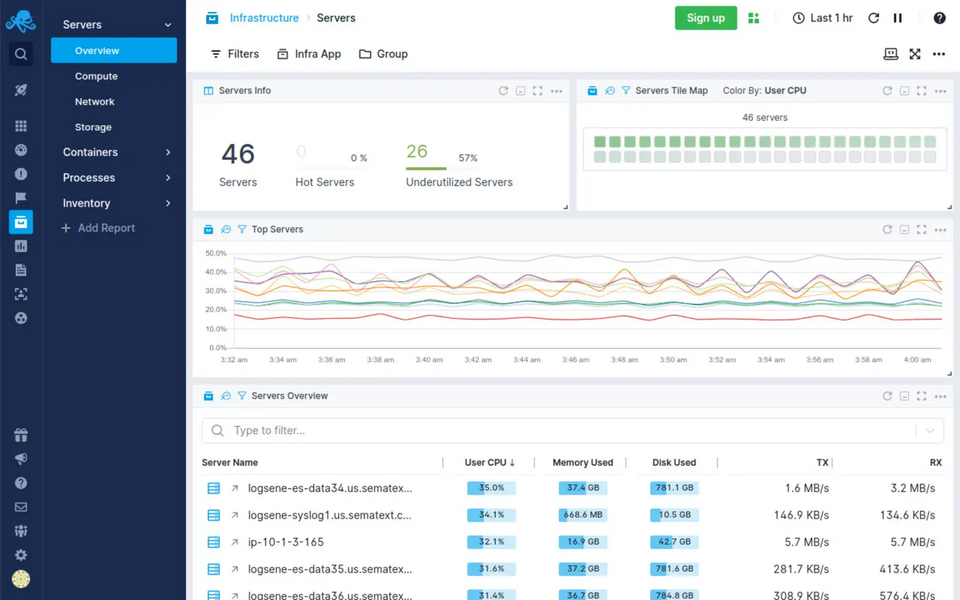
Źródło: Sematext
Zarządzanie logami realizowane jest przez usługę Sematext Logs, która zbiera komunikaty dziennika i analizuje w czasie rzeczywistym za pomocą hostowanej wersji stosu ELK w chmurze lub lokalnie. Narzędzie umożliwia przechowywanie, indeksowanie i przeszukiwanie logów różnego typu (logi aplikacji, serwera, kontenera, niestandardowych zdarzeń, aplikacji mobilnej) oraz agregowanie dzienników z wielu źródeł. Proces wysyłki logów odbywa się za pośrednictwem Elasticsearch API lub Syslog.
Alerty w Sematext służą do powiadamiania o spełnieniu co najmniej jednego z predefiniowanych warunków w metrykach, logach lub danych opartych o dane historyczne. Jako najważniejsze typy alertów należy wyróżnić:
- klasyczne alerty - oparte na progach i wyzwalane w momencie przekroczenia danego progu,
- anomalie - działają na podstawie statystyk i są wyzwalane, gdy wartości nagle zmieniają się i odbiegają od stale obliczanej linii bazowej,
- heartbeat - uruchamiane w momencie, gdy Sematext przez określony czas przestaje otrzymywać dane z serwera, kontenera, aplikacji itp.
Alerty integrują się m.in. z narzędziami Slack, PagerDuty, Teams, Google Chat, a także e-mailem.
Sematext rozwija się głównie w kierunku chmurowym, więc tym samym bardzo dobrze układa się współpraca z największymi cloudowymi dostawcami, czyli AWS, Microsoft Azure, Google Cloud Platform, DigitalOcean oraz IBM Cloud.
Sematext to potężny gracz na rynku monitoringu IT o czym świadczy fakt, że do jego klientów zaliczają się takie firmy jak eBay, Dell, Instagram czy Microsoft. Dla swoich klientów producent przygotował trzy plany – Basic, Standard i Pro dla każdego z czterech modułów: Logs, Monitoring, Experience, Synthetics. Każdy moduł można przetestować podczas 14-dniowego okresu próbnego. Sematext udostępnia interfejsy API InfluxDB i Elasticsearch dla metryk, dzienników i zdarzeń, dzięki czemu integracja z systemami zewnętrznymi jest prosta.
Narzędzia do monitorowania działania serwerów - podsumowanie
System monitoringu serwera umożliwia nieprzerwaną kontrolę środowiska IT. Właściwy wybór i wdrożenie narzędzia monitoringu zapewnia prawidłowe utrzymanie usług oraz bezpieczeństwo, stabilność i komfort prowadzenia biznesu. Odpowiednia konfiguracja z funkcją alertowania pozwala na szybką reakcję jeszcze przed wystąpieniem problemu w infrastrukturze. W ramach naszych usług DevOps możemy Cię wesprzeć w wyborze i wdrożeniu rozwiązania, które będzie najlepiej odpowiadało potrzebom Twojej firmy.









