

Ekstrakcja strukturalnych metadanych z dokumentów prawnych to jedno z najtrudniejszych zadań AI dla działalności regulowanych. Dzięki starannie zaprojektowanemu prompt engineeringowi z GPT-4o-mini i Structured Outputs OpenAI, zespoły mogą osiągnąć ponad 95% dokładności w kategoryzacji dokumentów regulacyjnych w wielu taksonomiach. Ten przewodnik pokazuje, jak BetterRegulation zbudowało produkcyjne szablony promptów, które niezawodnie wyodrębniają typy dokumentów, organizacje, obszary tematyczne i obowiązki prawne z brytyjskich i irlandzkich tekstów prawnych, skracając czas ręcznej korekty z 15 do 3 minut na dokument.
W tym artykule:
- Wyzwanie: ekstrakcja danych strukturalnych z nieustrukturyzowanego tekstu prawnego
- Dlaczego dokumenty prawne są tak trudne do przetwarzania przez AI?
- Jak wstrzykiwanie taksonomii poprawia dokładność ekstrakcji?
- Jak wymusić spójny output za pomocą schematu JSON?
- Jak działa dopasowanie semantyczne dla referencji encji?
- Jak optymalizować prompty dla lepszej dokładności?
- Jak wyodrębniać obowiązki prawne z dokumentów?
- Przykłady kodu i szablony promptów
- Prompt engineering do ekstrakcji danych – podsumowanie
- Potrzebujesz eksperckiego prompt engineeringu dla swojego projektu AI?
Wyzwanie: ekstrakcja danych strukturalnych z nieustrukturyzowanego tekstu prawnego
Dokumenty prawne zawierają ogromne ilości uporządkowanych informacji, ukrytych w gęstym i złożonym języku.
"The Financial Conduct Authority hereby issues this guidance pursuant to Section 139A of the Financial Services and Markets Act 2000, as amended by the Financial Services Act 2012, effective from 1 January 2024, applicable to all consumer credit lenders and hirers operating under Part II of the Consumer Credit Act 1974..."
Informacje ukryte w tym jednym zdaniu:
- Typ dokumentu: Guidance Note
- Organizacja: Financial Conduct Authority
- Legislacja: Financial Services and Markets Act 2000
- Rok: 2024
- Podmioty objęte regulacją: consumer credit lenders and hirers
Prawnik-człowiek wyodrębnia te dane natychmiast. AI potrzebuje precyzyjnych instrukcji i tu wkracza prompt engineering.
Ten artykuł pokazuje, jak pisać prompty, które niezawodnie wyodrębniają dane strukturalne z dokumentów prawnych, osiągając ponad 95% dokładności na produkcji.
Dlaczego dokumenty prawne są tak trudne do przetwarzania przez AI?
Zanim przejdziemy do metod, warto zrozumieć konkretne wyzwania, które sprawiają, że ekstrakcja danych z dokumentów prawnych jest trudna. Teksty prawne stawiają unikalne przeszkody, z którymi standardowe podejścia do przetwarzania tekstu nie radzą sobie skutecznie.
1. Skomplikowany język
Pisma prawne używają takich elementów językowych jak:
- Archaiczne terminy – „herein”, „whereas”, „aforementioned”.
- Zagnieżdżone klauzule – zdania rozciągające się na całe akapity.
- Żargon techniczny – „force majeure”, „res ipsa loquitur”.
- Niejednoznaczne odniesienia – „the aforementioned statute” (który dokładnie?).
2. Wiele taksonomii
Pojedynczy dokument może wymagać klasyfikacji w wielu wymiarach:
- Typ dokumentu (ustawa, rozporządzenie, wytyczne, orzecznictwo).
- Organizacja (organ wydający).
- Obszar tematyczny (bankowość, ochrona danych, zatrudnienie).
- Jurysdykcja (Wielka Brytania, UE, konkretne kraje).
- Legislacja (które akty prawne/rozporządzenia mają zastosowanie).
- Rok, data wejścia w życie, historia zmian.
Każda taksonomia zawiera od 10 do 400 terminów. To setki możliwych klasyfikacji.
3. Zmienne formaty
Żadne dwa dokumenty prawne nie strukturyzują informacji w ten sam sposób:
Ustawa:
Banking Act 2023
An Act to regulate...
Enacted by Parliament: 15 March 2023Wytyczne:
FCA Guidance Consultation Paper CP23/15
Published: December 2023
For: Banks and building societiesOrzecznictwo:
Regina v. Financial Conduct Authority [2023] UKSC 42
Supreme Court, 8 November 2023Te same informacje (typ, organizacja, data) w zupełnie różnych formatach.
4. Informacje ukryte vs jawne
Czasami informacja jest podana wprost: > „This regulation applies to all consumer credit lenders…”
Innym razem jest domniemana: > „Under Part II of the Consumer Credit Act…” (implikuje: dotyczy kredytodawców konsumenckich)
AI musi wnioskować na podstawie kontekstu.
Jak wstrzykiwanie taksonomii poprawia dokładność ekstrakcji?
Fundament dokładnej ekstrakcji: Powiedz AI o swoich taksonomiach z góry.
Dołączanie pełnych list taksonomii w kontekście
Zamiast: „Skategoryzuj ten dokument według typu, organizacji i obszaru.”
Napisz: „Dopasuj ten dokument do tych konkretnych taksonomii:”
### DOCUMENT TYPE TAXONOMY:
- Statute
- Regulation
- Guidance Note
- Code of Practice
- Case Law
### ORGANIZATION TAXONOMY:
- Financial Conduct Authority
- Bank of England
- Competition and Markets Authority
- Information Commissioner's Office
[... full list ...]
### DOCUMENT AREA TAXONOMY:
- Banking and Finance
- Consumer Credit
- Banking Regulation
- Data Protection
[... full list ...]Dlaczego to działa:
- Jasne granice – AI wie dokładnie, jakie opcje istnieją.
- Dopasowanie semantyczne – AI rozumie, że „FCA” = „Financial Conduct Authority”.
- Zwraca nazwy terminów – AI zwraca nazwy terminów (np.
["Data Protection", "Financial Services", "GDPR"]), które system następnie mapuje na identyfikatory terminów poprzez wyszukiwanie w taksonomii Drupala. - Brak halucynacji – AI nie wymyśla kategorii.
Jak to działa:
AI zwraca nazwy terminów taksonomii:
["Data Protection", "Financial Services", "GDPR"]System Drupala wykonuje wyszukiwanie w taksonomii: - „Data Protection” → znajduje ID terminu: 42 - „Financial Services” → znajduje ID terminu: 87 - „GDPR” → znajduje ID terminu: 156
Dokument otrzymuje przypisanie: [42, 87, 156]
To podejście wykorzystuje semantyczne rozumienie AI przy jednoczesnym zachowaniu precyzyjnych referencji encji dzięki systemowi taksonomii Drupala.
Czy koszt tokenów się opłaca?
„Ale czy to nie zużyje za dużo tokenów?“
Tak, zużywa tokeny. Ale się opłaca.
Liczby z BetterRegulation:
- Tekst dokumentu: 35 000 tokenów (typowy PDF na 50 stron).
- Kontekst taksonomii: 5 000 tokenów (wszystkie taksonomie).
- Instrukcje: 1 000 tokenów.
- Łącznie: 41 000 tokenów.
- Limit kontekstu: 128 000 tokenów (GPT-4o-mini).
- Zapas: 87 000 tokenów (spory margines).
Koszt:
- Z taksonomiami: £0,21 za dokument.
- Bez taksonomii (hipotetycznie): £0,18 za dokument.
- Dodatkowy koszt: £0,03 za dokument.
Wartość:
- Wzrost dokładności: 75% → 95%.
- Czas ręcznej korekty: 15 min → 3 min.
- Wartość oszczędności czasu: ponad £2,00 za dokument.
ROI: 70-krotny zwrot z inwestycji w tokeny taksonomii.
Jak wymusić spójny output za pomocą schematu JSON?
Gdy już dostarczysz AI taksonomie, kolejnym krokiem jest zapewnienie, że AI zwraca dane w spójnym, przetwarzalnym maszynowo formacie. Funkcja Structured Outputs OpenAI gwarantuje, że odpowiedzi zawsze odpowiadają Twojemu schematowi JSON.
Definiowanie dokładnej struktury wyjściowej
Ogólna instrukcja: > „Wyodrębnij typ dokumentu, organizację i rok.”
AI może zwrócić:
Document type is Guidance Note
Organization: FCA
Year: 2024Nie da się go automatycznie przetworzyć. Format zmienia się za każdym razem.
Lepiej: Użyj Structured Outputs OpenAI:
OpenAI udostępnia Structured Outputs, które gwarantują, że odpowiedź modelu będzie dokładnie odpowiadać Twojemu schematowi JSON. To podejście jest bardziej niezawodne niż JSON mode — zamiast po prostu otrzymać poprawny JSON, dostajesz JSON, który na pewno odpowiada dokładnie Twojemu schematowi.
Dwa dostępne podejścia:
- JSON Mode (
type: "json_object") – gwarantuje poprawny JSON, ale nie wymusza Twojego konkretnego schematu. - Structured Outputs (JSON Schema +
strict: true) – gwarantuje, że output odpowiada Twojemu dokładnemu schematowi (tego używa BetterRegulation).
Konfiguracja API ze Structured Outputs:
$response = $client->chat()->create([
'model' => 'gpt-4o-2024-08-06', // Structured outputs require gpt-4o models
'messages' => [
['role' => 'user', 'content' => $prompt]
],
'response_format' => [
'type' => 'json_schema',
'json_schema' => [
'name' => 'document_metadata',
'strict' => true, // ← Enforces strict schema compliance
'schema' => [
'type' => 'object',
'properties' => [
'document_type' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'organization' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'document_area' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'year' => ['type' => 'string'],
'title' => ['type' => 'string'],
'source_url' => ['type' => 'string']
],
'required' => ['document_type', 'organization', 'document_area', 'year', 'title'],
'additionalProperties' => false
]
]
],
'temperature' => 0.1,
]);Tekst promptu (instrukcje):
Analyze the document and extract:
- document_type: The primary document type (return taxonomy term name as string in array)
- organization: The issuing organization (return taxonomy term name as string in array)
- document_area: All relevant subject areas (return taxonomy term names as strings in array)
- year: Publication year in YYYY format
- title: Document title
- source_url: Full URL if found in document
Use ONLY taxonomy term names from the provided taxonomy lists. The system will map these names to term IDs automatically.Z Structured Outputs AI konsekwentnie zwraca:
{
"document_type": ["Guidance Note"],
"organization": ["Financial Conduct Authority"],
"document_area": ["Consumer Credit", "Banking Regulation"],
"year": "2024",
"title": "FCA Guidance on Consumer Credit Practices",
"source_url": "https://www.fca.org.uk/publication/guidance/gc24-1.pdf"
}Uwaga: System następnie wykonuje wyszukiwanie w taksonomii, aby przekonwertować nazwy terminów na identyfikatory: - „Guidance Note” → ID terminu: 14 - „Financial Conduct Authority” → ID terminu: 23 - „Consumer Credit” → ID terminu: 35 - „Banking Regulation” → ID terminu: 36
Dokument otrzymuje przypisanie: document_type: [14], organization: [23], document_area: [35, 36]
Wynik: 100% zgodności ze schematem, gwarantowane. BetterRegulation przetworzyło tysiące dokumentów z użyciem Structured Outputs bez ani jednego błędu walidacji schematu. Model nie może zwrócić danych niezgodnych z JSON Schema — OpenAI wymusza to na poziomie API, eliminując potrzebę rozbudowanej walidacji outputu w Twoim kodzie.
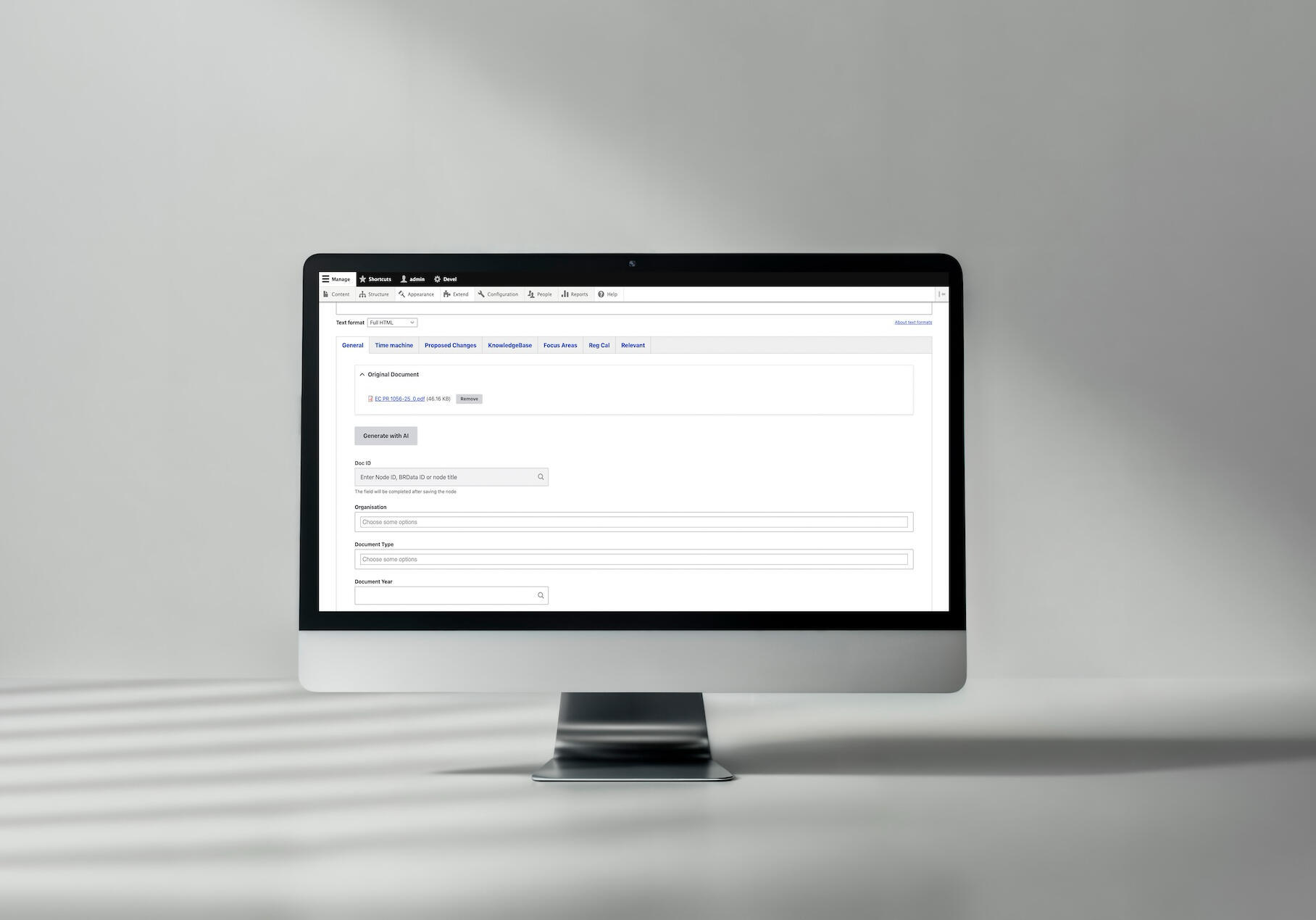
Przykład zastosowania kategoryzacji dokumentów opartej na sztucznej inteligencji dla Better Regulation
Zobacz pełne case study kategoryzacji dokumentów z AI →
Jak działa dopasowanie semantyczne dla referencji encji?
Gdy structured output jest już na miejscu, kolejnym wyzwaniem jest zapewnienie, że AI poprawnie mapuje zawartość dokumentu do Twoich konkretnych terminów taksonomii. Tu kluczowe staje się dopasowanie semantyczne — zdolność AI do rozumienia znaczenia, a nie tylko dokładnego dopasowania tekstu.
Jak AI dopasowuje terminy do taksonomii?
Sekret: AI rozumie znaczenie, nie tylko tekst.
Termin taksonomii: „Consumer Credit Lenders and Hirers”
Frazy z dokumentów, które AI skutecznie dopasowuje:
- „consumer lending practices”
- „personal loan providers”
- „credit companies offering hire purchase”
- „firms engaged in consumer finance”
- „lenders to individuals”
Jak? Duże modele językowe uczą się relacji semantycznych podczas treningu. Wiedzą, że:
- „lending” ≈ „lenders”
- „personal loan” ≈ „consumer credit”
- „hire purchase” → „hirers”
Tradycyjne dopasowanie słów kluczowych zawiodłoby w przypadku większości z tych wariantów.
Mechanizm mapowania nazw na identyfikatory
Kluczowa decyzja projektowa: AI zwraca nazwy terminów taksonomii, które system następnie mapuje na identyfikatory terminów poprzez wyszukiwanie w taksonomii Drupala.
Dlaczego to podejście działa:
// ✅ GOOD: AI returns term names
{
"organization": ["Financial Conduct Authority"],
"document_area": ["Data Protection", "Financial Services"]
}
// System performs taxonomy lookup
$organization_terms = \Drupal::entityQuery('taxonomy_term')
->condition('name', 'Financial Conduct Authority')
->condition('vid', 'organization')
->execute();
$area_terms = \Drupal::entityQuery('taxonomy_term')
->condition('name', ['Data Protection', 'Financial Services'], 'IN')
->condition('vid', 'document_area')
->execute();
// Map names to IDs
$organization_id = reset($organization_terms); // e.g., 23
$area_ids = array_values($area_terms); // e.g., [42, 87]
// Assign IDs to document
$node->set('field_organization', ['target_id' => $organization_id]);
$node->set('field_document_area', array_map(function($id) {
return ['target_id' => $id];
}, $area_ids));Korzyści podejścia opartego na nazwach:
- Dopasowanie semantyczne – AI wykorzystuje swoje rozumienie, aby semantycznie dopasowywać pojęcia, nawet gdy dokładne nazwy terminów nie występują w dokumencie.
- Elastyczność – jeśli terminy taksonomii zostaną zmienione, wyszukiwanie nadal działa (o ile nazwy się zgadzają).
- Czytelność – nazwy terminów są zrozumiałe dla człowieka, co ułatwia debugowanie i walidację.
- Precyzja – wyszukiwanie zapewnia dokładne dopasowanie w ramach słownika taksonomii, zapobiegając niejednoznaczności.
Jak to działa:
- AI zwraca nazwy terminów na podstawie semantycznego rozumienia dokumentu.
- System wykonuje wyszukiwanie w taksonomii, aby znaleźć pasujące identyfikatory terminów.
- Pola dokumentu są wypełniane identyfikatorami terminów jako referencje encji.
Jak obsługiwać niejednoznaczne terminy?
Niektóre terminy są rzeczywiście niejednoznaczne:
„ICO” może oznaczać: - Information Commissioner’s Office (ochrona danych) - Initial Coin Offering (kryptowaluty)
Strategia 1: Wskazówki kontekstowe w prompcie
If document discusses data protection, "ICO" likely means "Information Commissioner's Office".
If document discusses cryptocurrency, "ICO" likely means "Initial Coin Offering".
Use document context to disambiguate.Strategia 2: Dopuść wiele opcji
If ambiguous, return multiple possible term names:
{
"organization": ["Information Commissioner's Office", "Initial Coin Offering"]
}System wyszuka obie nazwy i zwróci ich identyfikatory. Recenzent następnie wybiera poprawną opcję z dostępnych.
Strategia 3: Ocena pewności (zaawansowana)
{
"organization": [
{"term_name": "Information Commissioner's Office", "confidence": 0.8},
{"term_name": "Initial Coin Offering", "confidence": 0.2}
]
}Wybierz opcję z najwyższą pewnością, a niską pewność (<0,7) oznacz do weryfikacji. System mapuje nazwy terminów na identyfikatory po dokonaniu wyboru.
Przeczytaj też: Automatyzacja przetwarzania dokumentów AI w Drupalu z 95% dokładnością: case study
Jak optymalizować prompty dla lepszej dokładności?
Nawet z odpowiednią strukturą i taksonomiami na miejscu, osiągnięcie wysokiej dokładności wymaga ciągłego udoskonalania. Oto jak systematycznie ulepszać prompty w oparciu o wyniki z produkcji.
Iteracyjny proces udoskonalania
Nie oczekuj idealnych promptów za pierwszym razem. Iteruj.
Używaj rzeczywistych dokumentów, nie syntetycznych przykładów.
Gdy nie masz pewności, które podejście jest lepsze, przetestuj oba:
Prompt A: Zwięzły
Categorize using these taxonomies:
[taxonomies]
Document:
[document]
Return JSON:
[schema]Prompt B: Rozbudowany
You are an expert legal document analyst. Your task is to carefully read
the provided document and categorize it according to the taxonomies below.
Instructions:
- Read the document thoroughly
- Identify the document type
- Determine the issuing organization
- Extract all relevant subject areas
[... detailed instructions ...]
Taxonomies:
[taxonomies]
Document:
[document]
Please return your analysis as JSON:
[schema]
Jak wyodrębniać obowiązki regulacyjne z dokumentów?
Wyodrębnianie obowiązków jest trudniejsze niż kategoryzacja, ponieważ:
- Ukryte obowiązki – nie zawsze są wprost sformułowane.
- Warunkowe obowiązki – „jeśli X, to musisz Y”.
- Identyfikacja zakresu – kto musi się zastosować?
- Wyodrębnianie terminów – do kiedy należy zapewnić zgodność?
Identyfikacja ukrytych obowiązków
Jawny obowiązek: > „All banks must submit quarterly reports to the FCA.”
Ukryty obowiązek: > „The Authority expects quarterly reporting from regulated entities.”
„Expects” implikuje obowiązek w kontekście regulacyjnym.
Wskazówki w prompcie:
Extract legal obligations including:
- MUST/SHALL/REQUIRED (explicit)
- SHOULD/EXPECTED/RECOMMENDED (strong guidance, often treated as obligations)
- Implicit requirements from regulatory context
For each obligation, extract:
- What action is required
- Who must perform it (affected parties)
- When it must be done (deadline/frequency)
- What happens if not done (consequences, if stated)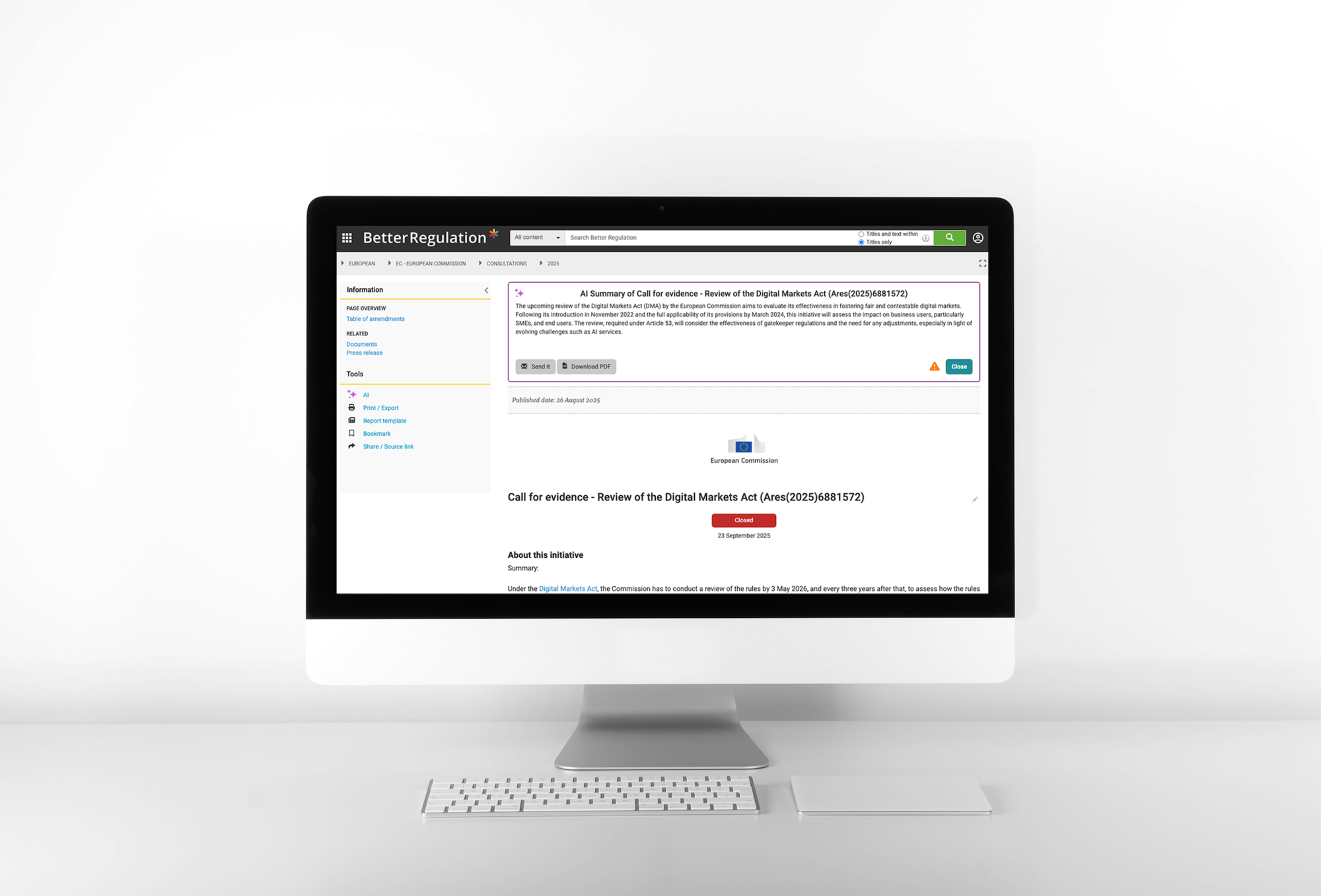
Przykład automatycznego tworzenia streszczeń dokumentów i wyodrębniania obowiązków regulacyjnych dla Better Regulation
Zobacz case study ze streszczeniami dokumentów i obowiązków regulacyjnych z AI →
Brakujące informacje
Co jeśli dokument nie zawiera oczekiwanych informacji?
Wskazówki w prompcie:
If information cannot be determined from document:
- Return empty array [] for that field
- Do NOT guess or invent information
- Do NOT return null or undefined
Example:
{
"source_url": "" // Not found in document
}
NOT:
{
"source_url": "https://www.example.com" // Don't make up URLs
}Wiele prawidłowych interpretacji
Niektóre dokumenty faktycznie pasują do wielu kategorii.
Przykład: Dokument omawia zarówno regulacje bankowe, jak i ochronę danych.
Strategia w prompcie:
document_area is a multi-value field.
If document covers multiple areas, include ALL relevant areas:
{
"document_area": ["Banking Regulation", "Data Protection"]
}
Prefer including all relevant areas over forcing single selection.
The system will map these term names to their corresponding IDs automatically.Przeczytaj też: AI Automators w Drupalu. Jak tworzyć wieloetapowe workflow AI?
Przykłady kodu i szablony promptów
Teraz, gdy omówiliśmy techniki, oto produkcyjne szablony promptów, które możesz zaadaptować do własnych projektów ekstrakcji danych z dokumentów prawnych. Szablony te uwzględniają wszystkie omówione wcześniej strategie.
Pełny prompt do kategoryzacji
You are analyzing a UK/Ireland legal or regulatory document.
Extract and categorize using these exact taxonomies.
CRITICAL RULES:
- Use ONLY taxonomy term names from lists below (return term names as strings)
- Return valid JSON in specified format
- Match by semantic meaning, not just keywords
- If multiple terms apply, include all relevant ones
- If uncertain, return empty array []
- The system will automatically map term names to term IDs
### DOCUMENT TYPE TAXONOMY:
- Statute
- Regulation
- Guidance Note
- Code of Practice
- Case Law
### ORGANIZATION TAXONOMY:
- Financial Conduct Authority
- Bank of England
- Competition and Markets Authority
- Information Commissioner's Office
- HM Treasury
[... full list ...]
### DOCUMENT AREA TAXONOMY:
- Banking and Finance
- Consumer Credit
- Banking Regulation
- Payment Services
- Data Protection
- Competition Law
[... full list ...]
### DOCUMENT TO ANALYZE:
{{ document_text }}
Return JSON with taxonomy term names (strings), not IDs.
Example:
{
"document_type": ["Guidance Note"],
"organization": ["Financial Conduct Authority"],
"document_area": ["Consumer Credit", "Banking Regulation"]
}
Prompt do ekstrakcji obowiązków regulacyjnych
Extract legal obligations from this document.
An obligation is a requirement that specific parties must fulfill.
For each obligation, identify:
- What action is required
- Who must perform it (affected parties/license types)
- When (deadline or frequency)
Include:
- Explicit obligations (MUST, SHALL, REQUIRED)
- Strong guidance (SHOULD, EXPECTED, RECOMMENDED)
- Implicit requirements from regulatory context
### LICENSE TYPES:
- Consumer Credit Lenders
- Consumer Credit Hirers
- Payment Services Providers
[... full list ...]
Return taxonomy term names (strings) for license types. The system will map these names to term IDs automatically.
### DOCUMENT:
{{ document_text }}
Prompt engineering do ekstrakcji danych – podsumowanie
Skuteczny prompt engineering do ekstrakcji danych z dokumentów prawnych wymaga takich akcji jak:
- Wstrzykiwanie taksonomii – dołączaj pełne listy taksonomii (tylko nazwy terminów; system mapuje nazwy na identyfikatory).
- Wymuszanie schematu JSON – definiuj dokładną strukturę wyjściową.
- Dopasowanie semantyczne – wykorzystuj rozumienie znaczenia przez AI.
- Iteracyjne udoskonalanie – testuj, mierz, ulepszaj.
- Analiza wzorców błędów – naprawiaj konkretne pomyłki systematycznie.
- Obsługa przypadków brzegowych – planuj na limity wielkości, brakujące dane, niejednoznaczności.
Wyniki BetterRegulation:
- Ponad 95% dokładności pól.
- Wskaźnik korekt edytorskich poniżej 5%.
- 2 miesiące iteracyjnego doskonalenia (75% → 95%).
- Comiesięczne udoskonalanie promptów w oparciu o analizę błędów.
Kluczowa lekcja: Prompt engineering to nie jednorazowe zadanie. To ciągłe doskonalenie oparte na wynikach z produkcji.
Zacznij prosto. Testuj dokładnie. Udoskonalaj systematycznie. Twoje prompty będą się z czasem poprawiać.
Potrzebujesz eksperckiego prompt engineeringu dla swojego projektu AI?
Ten przewodnik powstał na podstawie naszej produkcyjnej pracy nad prompt engineeringiem dla BetterRegulation, gdzie przez dwa miesiące opracowywaliśmy i udoskonalaliśmy prompty, osiągając ponad 95% dokładności w ekstrakcji danych z dokumentów prawnych. Kluczem była systematyczna iteracja: zaczynając od podstawowych promptów z 75% dokładnością, analizując wzorce błędów, udoskonalając instrukcje i stopniowo poprawiając wyniki do poziomu produkcyjnego. To iteracyjne podejście do prompt engineeringu przekształciło prototyp w niezawodny system przetwarzający tysiące dokumentów miesięcznie.
Budowanie skutecznych promptów wymaga zarówno wiedzy technicznej, jak i zrozumienia dziedziny. Nasz zespół specjalizuje się w prompt engineeringu do zadań ekstrakcji danych. Obsługujemy pełny cykl: projektowanie promptów, integrację taksonomii, definicję schematów JSON, iteracyjne testowanie, analizę błędów i ciągłą optymalizację. Odwiedź stronę naszych usług rozwoju generatywnej sztucznej inteligencji, aby dowiedzieć się, jak możemy Ci pomóc.










